Mình đã chuyển thachpham.com qua headless ra sao? Kinh nghiệm thực tế từ A đến Z
Các đoạn code cung cấp trong bài này ở dạng mô phỏng để phù hợp để dễ hiểu, không phản ánh chính xác code trong dự án thật của mình.
Sau hơn 10 năm blog thachpham.com gắn bó với mã nguồn WordPress truyền thống, mình quyết định chuyển kiến trúc của blog sang sử dụng WordPress như một Headless CMS – nghĩa là WordPress giờ đây chỉ được sử dụng đúng với thế mạnh của nó: Quản trị nội dung. Còn phần giao diện hiển thị ra bên ngoài được xây dựng riêng thông qua các framework như Nuxt, Astro, Next.js,…
Trong bài này mình sẽ kể ra việc tại sao mình quyết định chuyển blog thachpham.com sang dùng headless, các thách thức mình đã gặp cùng với cách giải quyết, và quy trình mình xây dựng nó như thế nào với sự hỗ trợ của Claude Code.
Ghi chú: Tại sao lại là Claude Code mà không phải Antigravity hay ChatGPT Codex? Vì mình quen dùng Claude Code trên terminal, mình không quen dùng các IDE AI như Antigravity hay Cursor. Mình vẫn sử dụng IDE VSCode để kiểm tra code, nhưng không dùng AI tại đó.
Giải thích thuật ngữ
Bài viết này dùng khá nhiều thuật ngữ kỹ thuật. Nếu bạn đã quen với phát triển web hiện đại thì có thể bỏ qua phần này. Còn nếu bạn đến từ thế giới WordPress truyền thống, đọc qua một lượt sẽ giúp bạn theo dõi bài viết dễ hơn.
Frontend và Backend – Trong WordPress truyền thống, hai phần này gộp chung làm một: PHP vừa xử lý logic vừa render giao diện. Khi nói “headless”, tức là tách chúng ra. Backend là WordPress – nơi bạn viết bài, quản lý dữ liệu. Frontend là một ứng dụng riêng biệt (viết bằng React, Astro, Next.js…) – nơi hiển thị nội dung cho người đọc. Hai bên giao tiếp với nhau qua API.
API (Application Programming Interface) – Cách để hai phần mềm nói chuyện với nhau. Trong ngữ cảnh headless WordPress: frontend gửi yêu cầu “cho tôi 10 bài viết mới nhất”, backend trả về dữ liệu dạng JSON. Không có giao diện, không có HTML mà chỉ có dữ liệu thô. WordPress có sẵn REST API từ phiên bản 4.7, nhưng bài viết này chủ yếu dùng GraphQL.
GraphQL – Một ngôn ngữ truy vấn dữ liệu, thay thế cho REST API. Với REST, bạn gọi một URL cố định và nhận về toàn bộ dữ liệu (dù bạn chỉ cần tiêu đề bài viết, nó vẫn trả về cả nội dung, tác giả, comment…). Với GraphQL, bạn chỉ định chính xác mình cần gì và chỉ nhận về đúng những gì mình yêu cầu. Trong WordPress, plugin WPGraphQL cung cấp khả năng này.
Cache – Bản sao dữ liệu được lưu tạm ở bộ nhớ hoặc lưu trên CDN, để không phải gọi lại các bu. Ví dụ: thay vì mỗi lượt truy cập đều gọi GraphQL để lấy bài viết, kết quả được lưu trong Redis (cache ở server) hoặc Cloudflare (cache ở edge gần người dùng). Lần truy cập sau lấy từ cache — nhanh hơn hàng chục lần.
CDN (Content Delivery Network) – Mạng lưới máy chủ phân tán khắp thế giới. Khi người đọc ở Việt Nam truy cập website, họ nhận nội dung từ server gần nhất (Singapore, Hong Kong hoặc thậm chí là từ ngay Việt Nam) thay vì phải đi đến server gốc ở xa. Trong bài viết này, Cloudflare đóng vai trò CDN, vừa cache nội dung, vừa phục vụ hình ảnh, vừa bảo vệ website.
Webhook – Cơ chế “gọi điện thông báo” giữa hai hệ thống. Thay vì frontend phải liên tục hỏi backend “có bài mới chưa?” (polling), backend sẽ chủ động gọi đến một URL của frontend ngay khi có thay đổi. Ví dụ: bạn nhấn Publish trong WordPress → WordPress gửi webhook đến frontend → frontend xóa cache cũ và cập nhật nội dung mới.
SSR (Server-Side Rendering) – Mỗi khi có người truy cập, server chạy code để tạo ra trang HTML hoàn chỉnh rồi gửi về trình duyệt. Trang luôn cập nhật vì được render mới mỗi lần, nhưng server phải làm việc nhiều hơn. Đây là cách thachpham.com đang hoạt động: Astro server nhận request → gọi GraphQL (hoặc lấy từ cache) → render HTML → trả về cho người đọc.
SSG (Static Site Generation) – Toàn bộ trang HTML được tạo sẵn một lần tại thời điểm build (deploy). Khi có người truy cập, server chỉ việc trả file HTML có sẵn — cực nhanh, không cần xử lý gì. Nhược điểm: mỗi khi nội dung thay đổi, phải build lại. Với blog vài chục bài thì không sao, nhưng website hàng nghìn bài thì mỗi lần build có thể mất 10-15 phút. Triển khai phương án này có thể phải cần cơ chế build độc lập mỗi khi có sự thay đổi.
ISR (Incremental Static Regeneration) – Giải pháp lai giữa SSG và SSR, phổ biến trong Next.js. Trang được tạo sẵn như SSG, nhưng sau một khoảng thời gian (ví dụ 60 giây), lượt truy cập tiếp theo sẽ kích hoạt server tạo lại trang mới ở background. Người dùng hiện tại vẫn nhận trang cũ (nhanh), người dùng sau đó nhận trang mới (cập nhật). Cân bằng giữa tốc độ và độ tươi mới của nội dung.
WordPress Headless là gì?
Đây là khái niệm cũng không phải mới, nhưng mình nghĩ rằng sẽ có nhiều bạn ở đây sẽ chưa biết về khái niệm này một cách dễ hiểu nhất. Cũng nói thêm rằng, Headless ở đây có nghĩa là không có đầu, không phải chuyện kinh dị gì đâu chỉ là thuật ngữ thôi.
Hãy tưởng tượng một website WordPress truyền thống như một nhà hàng mà đầu bếp (backend) vừa nấu ăn, vừa bưng ra bàn, vừa trang trí món ăn (frontend). Mọi thứ gói gọn trong một người, tiện thì tiện, nhưng khi nhà hàng đông khách thì…tạch.
WordPress Headless giống như bạn tách riêng đầu bếp ra hẳn trong bếp, còn phần phục vụ bàn giao cho một đội ngũ chuyên nghiệp khác. Đầu bếp chỉ lo nấu ăn (quản lý nội dung), xong đưa ra quầy (API). Đội phục vụ (frontend framework) nhận đồ ăn từ quầy rồi tự lo trình bày, trang trí, bưng ra cho khách.

Nói cách khác thì:
WordPress vẫn là nơi bạn viết bài, upload ảnh, quản lý category,… mọi thứ y hệt như trước, vẫn dùng wp-admin quen thuộc. Nhưng thay vì WordPress tự render HTML bằng PHP theme, nó chỉ cung cấp dữ liệu dạng JSON thông qua API (REST/GraphQL).
Ở phía giao diện website (frontend) sẽ tách riêng biệt (Astro, Next.js, Nuxt, hay bất kỳ framework nào) sẽ nhận dữ liệu JSON đó và tự render giao diện ra cho người dùng nhìn thấy.
Cái “đầu” (head) bị bỏ đi đi chính là phần theme PHP truyền thống. Còn “cơ thể” WordPress vẫn hoạt động bình thường. Headless = không đầu nghĩa là vậy đó.
Vì sao mình lại muốn chuyển sang sử dụng WordPress như headless CMS?
Nói thật, mình không ghét WordPress truyền thống mà thậm chí còn yêu nó. Mình đã dùng nó từ 2007 tới nay và nó đã phục vụ mình rất tốt. Nhưng hiện nay việc viết code không còn là trở ngại khi có sự hỗ trợ của các công cụ AI như Claude Code, Antigravity, ChatGPT Codex,…thì việc sử dụng WordPress như một headless CMS sẽ có nhiều ưu thế hơn (đối với mình).
WordPress là một mã nguồn rất tốt, phổ biến nhất hành tinh này, nhưng không phải là không có các nhược điểm và đây chính là lý do mình sử dụng như một headless CMS.
Vấn đề 1: Hiệu năng cứ nằm ở mức “trần” nào đó
WordPress truyền thống hoạt động theo cơ chế: mỗi request → PHP bootstrap WordPress core → load plugins → query database → render template → trả HTML. Dù bạn có dùng object cache, page cache, CDN, hay tối ưu database queries đến đâu, quá trình khởi tạo PHP + WordPress core vẫn tốn thời gian.
Nghiên cứu của WP Engine1 cho thấy dưới 30% website WordPress truyền thống đạt Core Web Vitals tốt, trong khi hơn 50% các frontend framework hiện đại thường xuyên đạt ngưỡng “healthy”. Mình muốn thachpham.com nằm trong nhóm 50% đó.
Nhiều bạn sẽ nói là có rất nhiều cách để tối ưu một website WordPress thông thường để có hiệu năng tốt, và đạt điểm Core Web Vitals tốt. Mình hoàn toàn đồng ý, nhưng ngay cả khi tối ưu thì vẫn có các nhược điểm riêng như:
- Quản lý các tập tin assets như CSS, JS trong WordPress rất khó khăn khi mỗi plugin/theme lại chèn một kiểu.
- Khi website có nhiều bài viết, và kèm theo danh sách 20, 30 plugin thì tối ưu và server mạnh đến đâu vẫn có khả năng bị nghẽn cổ chai ở đâu đó.
Nói theo cách ngắn gọn, WordPress thông thường vẫn có thể tối ưu được nhưng sẽ mất thời gian và công sức hơn nhiều.
Vấn đề 2: Bảo mật – nỗi lo lớn nhất của WordPress
Theo báo cáo Patchstack 2024 mà mình đã có đề cập trong serie WordPress Tinh Gọn 2024, 97% lỗ hổng bảo mật WordPress đến từ plugin. Bạn không đọc nhầm đâu, 97% lỗ hổng đến từ các plugin.
Không phải core WordPress không an toàn, mà vì hệ sinh thái plugin quá phong phú (và chất lượng thì… rất phong phú theo cả hai hướng), bạn lỡ dùng 1 plugin mà có lỗ hổng là khả năng bị khai thác sẽ đến rất sớm thôi.

Mỗi plugin bạn cài thêm là thêm một cánh cửa có thể bị mở toang. Và bạn biết cánh cửa lớn nhất dẫn kẻ xấu xâm nhập vào website của bạn ở đâu không? Chính là wp-login.php để bạn đăng nhập vô wp-admin đấy, khi có hàng triệu lượt con bot chuyên đi rình mò website đặt mật khẩu sơ hở hoặc dùng lại mật khẩu đã bị lộ để đăng nhập vào.
Khi dùng WordPress headless, mình có thể:
- Ẩn hoàn toàn WordPress khỏi public internet nếu muốn (như cách mình đang làm). Backend WordPress của mình hiện chỉ truy cập được qua tailnet riêng (dùng Tailscale). Bot không tìm thấy, hacker không tấn công được.
- Frontend chỉ là HTML/CSS/JS tĩnh, không có database connection để khai thác, không có PHP code để injection.
- Ngay cả khi frontend có nguy cơ bảo mật bằng cách nào đó, backend vẫn an toàn trong private network.
- API cũng đặt trong tailnet, không thể truy cập từ bên ngoài (frontend vẫn nằm trong tailnet nên truy cập được), dễ dàng kiểm soát với middleware chặt chẽ.
Đây là lý do thuyết phục nhất với mình. Không phải hiệu năng, mà là sự yên tâm khi đi ngủ.
Vấn đề 3: Theme
Phần này mình cũng không biết đặt tiêu đề sao nên mình tạm ghi là Theme, nhưng đúng với vấn đề mình gặp luôn đó là Theme.
Trong WordPress, nếu bạn tự làm theme cho riêng mình thì việc templating bằng PHP hiện nay nhìn chung khá…củ chuối về mặt tối ưu workflow, trong khi các công cụ/framework hiện đại ngày nay hỗ trợ cho việc build frontend rất phong phú nhưng khó áp dụng được.
Theo quy trình frontend hiện đại ngày nay, sẽ có các công cụ tối ưu cơ bản như sau mà WordPress hiện nay khó có thể áp dụng được (vẫn có cách nhưng rất mất thời gian):
- Hot Module Replacement (HMR): Sửa code → trình duyệt cập nhật tức thì, không cần reload.
- Component-based architecture: Tái sử dụng UI components dễ dàng.
- Các công bụ hỗ trợ build hiện đại (Vite, Webpack,…) có thể tree-shaking tự động, code splitting hay minify các tập tin assets.
Các nhược điểm trên có thể phần nào khắc phục nếu dùng các plugin thiết kế trang kéo thả như Elementor, Bricks nhưng lúc này mình mất đi sự tự do trong frontend, trang sẽ nặng thêm.
Nói thật lòng nhé, mình không thích cách làm theme trong WordPress, nên đó giờ mình hầu như không tự làm theme cho riêng mình mà đi sử dụng lại theme có sẵn cho nhanh và đỡ nhức đầu.
Vấn đề 4. Vibe Coding trong WordPress
Nếu bạn đang theo dõi xu hướng vibe coding – cách tiếp cận lập trình mà bạn chỉ cần mô tả ý tưởng cho AI rồi để nó lên kế hoạch, tự code, tự test và ship luôn thì WordPress truyền thống là một trong những môi trường tệ nhất để làm điều đó.

Thử tưởng tượng bạn muốn tuỳ biến giao diện một trang WordPress…
Đầu tiên, bạn cần dựng cả một môi trường localhost dưới máy tính: cài phần mềm LocalWP rồi import database, copy toàn bộ mã nguồn về, bao gồm cả wp-content với hàng chục (hoặc hàng chục nghìn tấm ảnh như thachpham.com), đống plugins và theme. Chưa kể phải xử lý đường dẫn, cấu hình wp-config.php, và cầu nguyện rằng phiên bản PHP trên máy mình tương thích với tất cả các plugin đang dùng.
Rồi đến phần code. WordPress sử dụng hệ thống Template Hierarchy – một chuỗi ưu tiên các file PHP như single.php, page.php, archive.php, index.php… Mỗi theme lại tổ chức khác nhau. Theme dùng Elementor thì logic nằm trong database dưới dạng serialized data. Theme dùng block editor (FSE) thì template nằm trong theme.json và các file HTML trong thư mục templates/. Theme truyền thống còn gớm hơn, PHP thuần trộn lẫn HTML. Muốn sửa một cái gì đó, bạn phải hiểu cách theme đó hoạt động trước – và đây là thứ mà AI rất khó giúp bạn nếu nó không “nhìn thấy” toàn bộ context.
Tệ hơn, frontend của WordPress truyền thống bị gắn chặt với backend. Mỗi khi người dùng truy cập một trang, server phải query database, chạy qua hàng loạt PHP hooks (init, template_redirect, wp_head, the_content…), load theme, load tất cả plugin đang kích hoạt, render HTML rồi mới trả về. Một trang WordPress trung bình load khoảng 20-30 file CSS/JS từ các plugin khác nhau. Theme nặng như Divi hay Elementor còn kéo thêm hàng trăm KB JavaScript của riêng chúng. Bạn muốn thay đổi một component nhỏ trên frontend? Bạn phải hiểu nó đến từ theme, từ plugin nào, hook vào đâu, và liệu thay đổi của bạn có bị plugin khác ghi đè không.
Đó là lý do vibe coding với WordPress truyền thống rất bị hạn chế. AI có thể generate code PHP cho bạn, nhưng code đó chạy được hay không phụ thuộc vào theme đang dùng, các plugin đang kích hoạt, phiên bản PHP, và hàng tá biến số mà AI không thể biết trước.
Với Headless WordPress thì hoàn toàn khác...
Bạn chỉ cần một thứ: URL endpoint của API (REST API hoặc GraphQL). Không cần cài PHP. Không cần MySQL trên máy local. Không cần biết theme trên WordPress là gì. Bạn mở terminal, chạy npm create astro@latest, trỏ đến API endpoint, và bắt đầu vibe coding ngay lập tức. Bạn có thể nói với AI: “Tạo cho mình một trang blog list dùng Astro, fetch data từ endpoint GraphQL này, style với Tailwind”, và code generate ra sẽ chạy được luôn, vì nó không phụ thuộc vào bất kỳ theme, plugin, hay template hierarchy nào.
Mình không cố gắng cổ xuý vibe-coding mà không xem qua mà ngược lại, bạn phải hoàn toàn kiểm soát được AI đã code những gì, bạn phải là người quyết định nó sẽ làm gì, bảo mật như thế nào và hoàn toàn hiểu được logic code mà nó viết.
Mình đã trải nghiệm điều này trực tiếp khi chuyển thachpham.com sang headless. Với WordPress truyền thống, mỗi lần muốn sửa giao diện, mình phải SSH vào server hoặc dựng local environment, tìm đúng file template trong theme, đọc hiểu logic PHP xen lẫn HTML, rồi mới sửa được, hoặc là đi mò mẫm trong giao diện Elementor. Với Headless + Astro, mình chỉ cần mở VS Code, gõ prompt cho Claude Code, và nó generate ra component mới trong vài giây – không dependency, không xung đột gì đến backend, không phải dè chừng plugin nào cả. Toàn bộ frontend là của mình, mình kiểm soát 100%. Đây là lý do mà giao diện thachpham.com hiện nay hầu như có các tính năng khó để tìm thấy trên các website WordPress thông thường, dù nó vẫn là WordPress theo một cách khác.
WordPress REST API đã được tích hợp vào core từ phiên bản 4.7 (tháng 12/2016), và WPGraphQL ra đời cùng năm đó bởi Jason Bahl – hiện là Principal Software Engineer tại Automattic và đang phát triển WPGraphQL thành canonical plugin chính thức. Nghĩa là WordPress đã sẵn sàng cho headless từ lâu, chỉ là phần lớn người dùng chưa khai thác được tiềm năng này.
Nói cách khác: Headless WordPress biến WordPress từ một hệ thống mà bạn phải “chiến đấu” với nó để tuỳ biến, thành một hệ thống chỉ đơn giản cung cấp dữ liệu cho bạn xây dựng bất cứ thứ gì bạn muốn. Và trong thời đại trợ lý AI phát triển rất nhanh, đây chính xác là thứ mà bạn sẽ cần.
Lựa chọn Tech Stack
Trước khi bắt đầu việc chuyển trang thachpham.com (và cả azdigi.com nữa) qua WordPress headless, mình đã nghiên cứu rất nhiều để có thể chọn được những công nghệ mà mình cần sử dụng để đạt hiệu quả tối ưu cao. Dưới đây là các kinh nghiệm của mình trong việc lựa chọn tech stack để triển khai.
| Thành phần | Công nghệ | Tại sao? |
|---|---|---|
| Frontend Framework | Astro v5 (Hybrid mode) | SSR native, partial hydration, content-focused, zero JS by default |
| UI Components | Svelte 5 | Bundle size nhỏ nhất, compile-time reactivity, không ship runtime |
| Styling | Tailwind CSS v4 | Utility-first, design tokens, JIT compilation |
| CMS Backend | WordPress + WPGraphQL | Giữ nguyên content hiện tại, UI quản lý quen thuộc |
| Cache Layer | Redis | BFF caching pattern, TTL linh hoạt theo loại content |
| Search | ElasticPress | Full-text search tiếng Việt, tính năng bài liên quan với thuật toán More Like This |
| Comments | Giscus | GitHub-based, không cần database riêng, markdown support |
| SEO | Custom JSON-LD + Rank Math (data source) | Full control output, Rank Math chỉ cung cấp data |
REST API vs WPGraphQL: Vì sao mình chọn WPGraphQL
WordPress có sẵn REST API từ phiên bản 4.7 (2016). Bạn không cần cài thêm gì cả. Gõ thử yoursite.com/wp-json/wp/v2/posts trên thanh địa chỉ trình duyệt, bạn sẽ thấy toàn bộ bài viết dưới dạng JSON.
REST API hoạt động theo kiểu: mỗi endpoint trả về một loại dữ liệu. Muốn lấy bài viết? Gọi /posts. Muốn lấy danh mục? Gọi /categories. Muốn lấy bài viết kèm ảnh đại diện và tác giả? Gọi /posts?_embed. Đơn giản, dễ hiểu, nhưng đôi khi bạn phải gọi nhiều lần mới đủ dữ liệu cần thiết.
WPGraphQL là một plugin miễn phí để ứng dụng ngôn ngữ GraphQL để làm API cho WordPress, nó sẽ tạo ra một endpoint GraphQL duy nhất. Ưu điểm lớn nhất là bạn chỉ cần một request để lấy chính xác những gì bạn cần. Muốn lấy 10 bài viết mới nhất, kèm tên tác giả, 2 danh mục đầu tiên, và URL ảnh đại diện? Một query duy nhất. Không thừa, không thiếu.
{
posts(first: 10) {
nodes {
title
slug
date
excerpt
author {
node {
name
}
}
categories(first: 2) {
nodes {
name
slug
}
}
featuredImage {
node {
sourceUrl
altText
}
}
}
}
}Với REST API, bạn cần gọi /posts?_embed&per_page=10 rồi parse một đống dữ liệu thừa. Với GraphQL, bạn chỉ nhận đúng những field liệt kê. Theo benchmark, payload có thể giảm từ hàng trăm KB xuống chỉ vài KB cho cùng một dataset.
Khỏi phải nói cũng biết, mình chọn WPGraphQL cho thachpham.com. Lý do đơn giản: dữ liệu gọn hơn, ít request hơn, và code frontend sạch hơn. Plugin này cũng đã được Automattic (công ty mẹ của WordPress.com) chính thức tài trợ từ tháng 10/2024, nên bạn không cần lo về chuyện bị bỏ rơi.
Tại sao Astro mà không phải Next.js?
Next.js là một React framework rất phổ biến và hot ở thời điểm hiện tại, vì vậy câu hỏi này chắc chắn sẽ được hỏi, nên mình trả lời luôn.
Next.js là framework tuyệt vời, nhưng nó được thiết kế cho application – nơi hầu hết các thành phần có sự tương tác và dữ liệu động. Một blog cá nhân thì ngược lại: 95% nội dung là văn bản và hình ảnh.
Astro được thiết kế đặc biệt cho các website thiên về nội dung (nên họ mới ghi là The web framework for content-driven websites) với triết lý “ship less JavaScript”. Mặc định, Astro gửi zero JavaScript đến browser. Chỉ những component bạn đánh dấu rõ ràng (client:load, client:idle, client:visible) mới được kích hoạt tương tác (hydrate) ra trình duyệt. Đây chính là điểm mạnh của Astro mà được họ gọi là kiến trúc Island (Islands architecture2) khi các component được gọi là “đảo” độc lập giữa một “vùng biển” HTML.
<!-- Hydrate ngay khi page load -->
<Counter client:load />
<!-- Hydrate khi trình duyệt idle -->
<Newsletter client:idle />
<!-- Hydrate khi component vào viewport -->
<ImageCarousel client:visible />Chính vì sự linh hoạt độc đáo này, bạn có thể dễ dàng điều khiển thành phần nào được hydrate trước ưu tiên, cái nào ít ưu tiên hơn thì load khi trình duyệt đã xử lý xong các tác vụ quan trọng, cái nào chỉ cần load khi nó xuất hiện trong viewport trình duyệt, từ đó giúp dễ dàng tối ưu điểm Core Web Vitals và đạt điểm cao trên Google Pagespeed.

Theo báo cáo HTTP Archive3, 67% website Astro đạt good Core Web Vitals, so với WordPress (30%), Gatsby (39%), Next.js (27,5%), và Nuxt (20%). Đọc con số thôi là nói lên được tất cả rồi.
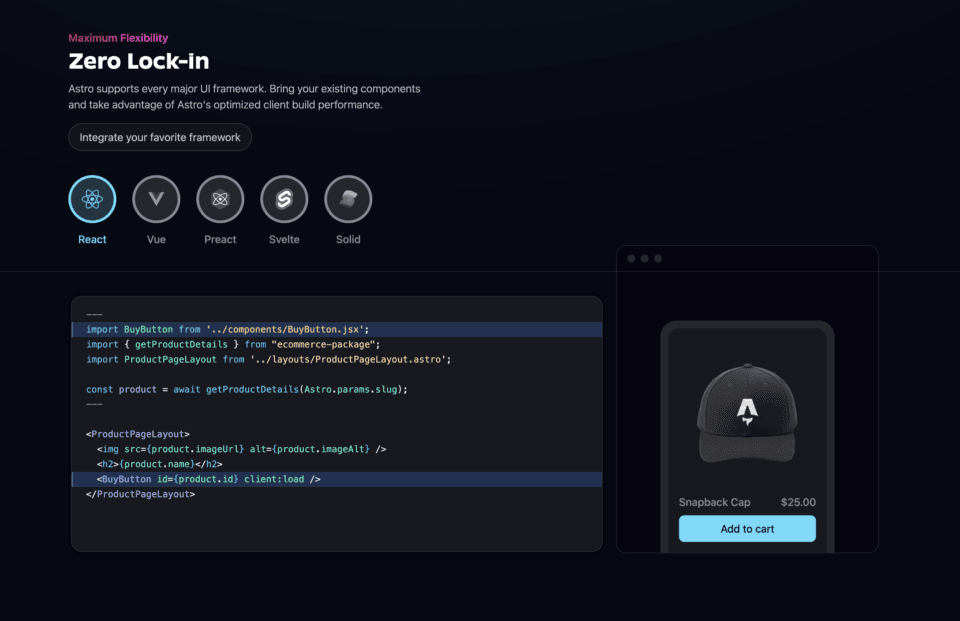
Và một điểm cộng lớn nữa đó là Astro là framework agnostic. Mình dùng Svelte cho interactive components, nhưng nếu mai muốn chuyển sang React cho một component cụ thể? Cứ import vào, Astro xử lý hết, thậm chí còn không cần thay đổi code của Astro nếu muốn refactor toàn bộ qua framework khác.
Hybrid rendering mode
Astro hỗ trợ 3 output modes: static (default, pre-render tất cả thành HTML tĩnh), server (chỉ render khi yêu cầu), và hybrid (pre-render by default, opt-out cho specific routes). Điều này cho phép:
- Trang chủ → Static generation
- Nội dung bài viết → Server-side rendering để cập nhật trực tiếp
- Kết quả tìm kiếm → Server-side rendering
Hoặc nếu website của bạn ít trang, bạn có thể build hoàn toàn dạng static (HTML tĩnh) và deploy lên các nền tảng như Cloudflare Pages, Vercel hoặc Netlify. Cách này không cần chạy server backend riêng và gần như không phải quản trị hosting/VPS truyền thống.
Còn nếu trang có sử dụng Server-side rendering thì sẽ cần hosting/VPS hỗ trợ node.js hoặc dùng Docker để chạy.
Tại sao Svelte mà không phải React?
Thực ra mình chọn sử dụng React trước vì nó phổ biến nhất, nhưng sau khi đã hoàn thiện phần lớn thì sau khi build ra, frontend phải luôn load một file runtime có kích thước khá lớn, kể cả sau khi gzip lại thì nó vẫn còn đến 50KB, trong khi một trang blog như thachpham.com thì các component cần sự tương tác không nhiều vì chủ yếu là nội dung. Sau đó mình nghiên cứu và chọn Svelte 5 thay thế.
Svelte 5 biên soạn thành Javascript thuần (Vanilla Javascript) trong quá trình build. Không có virtual DOM, không có runtime. Phần nào nào cần hydrate thì Astro chỉ gửi đúng code của phần đó, không kèm theo framework runtime nào cả.
Kết quả: JS bundle của thachpham.com chỉ ~40KB cho toàn bộ site (không bao gồm CSS và các hình ảnh, HTML), bao gồm navigation, search, code highlighting, YouTube lazy loading, comments, và pagination. Nếu dùng React, dung lượng phần này dễ dàng đạt gấp đôi hoặc gấp 3 lần.
Nhược điểm và các thách thức khi dùng WordPress headless
Việc sử dụng WordPress như một headless CMS với frontend tách rời lợi thì có rất nhiều nhưng hại thì cũng đủ đường. Khi sử dụng theo hướng này, bạn phải chấp nhận đánh đổi giữa việc tự do tuỳ biến, bảo mật, hiệu năng với độ phức tạp khi quản trị và nhiều việc cần phải làm hơn.
1. Mất toàn bộ hệ sinh thái theme và plugin frontend

Đây là sự đánh đổi lớn nhất. WordPress có 59,000+ themes và hàng chục ngàn plugins. Chuyển sang headless, bạn mất tất cả. Mọi giao diện phải build từ đầu.
Page builders (Elementor, Divi, WPBakery) không hoạt động. Contact Form 7 không hoạt động. WP Rocket không cần thiết (nhưng cũng không hoạt động). Plugin cache, SEO plugins (phần frontend output), comment plugins — tất cả cần thay thế hoặc tự build.
Mình phải tự làm các tính năng sau: search (dùng ElasticPress), comments (Giscus), form liên hệ (custom + Telegram/Email), sitemap, JSON-LD, bảo mật API,… Mỗi thứ không quá phức tạp, nhưng tổng lại thì đây là lượng công việc đáng kể.
2. Việc xem trước bài viết sẽ phức tạp hơn
Với WordPress truyền thống, bạn click Preview là xem được trước bài viết được render ra frontend ra sao, rất đơn giản.
Nhưng với headless, nút Preview mặc định không hoạt động. Muốn xem trước, bạn cần tạo preview route trên frontend, sử dụng các cơ chế xác thực phức tạp để lấy nội dung nháp ra mà xem trước, sau đó viết code tuỳ chỉnh trong WordPress (hoặc tự làm bộ plugin riêng) để filter link Preview sử dụng frontend bên ngoài.
Có các giải pháp có sẵn (Faust.js, HeadstartWP), nhưng setup phức tạp hơn nhiều so với một cú click chuột vốn có sẵn trong WordPress.
Cá nhân mình giải quyết bằng cách… chấp nhận. Bài viết của mình cũng không làm layout phức tạp, xem trước ở Block Editor đã đủ dùng, viết xong thì đăng lên luôn khỏi xem trước gì cả.
3. Hai hệ thống cần bảo trì
Thay vì tập trung bảo trì một nơi như WordPress thông thường, giờ bạn cần bảo trì: WordPress backend + frontend + Redis + ElasticSearch (nếu dùng) + CI/CD pipeline (nếu muốn quy trình tự động). Nhiều thứ hơn = nhiều thứ có thể hỏng hơn.
4. Rào cản kỹ thuật cao
WordPress headless hay WordPress thường thì cũng xây dựng bằng code, nhưng mình thấy dùng WordPress headless cần hiểu rõ về các kiến thức bên dưới để có thể quản trị một cách thoải mái nhất:
- WordPress development (PHP, REST API/GraphQL)
- Frontend framework (Astro/React/Vue, JavaScript/TypeScript)
- Server management (Node.js hosting, reverse proxy)
- Caching strategies (Redis, CDN configuration)
- CI/CD (GitHub Actions, deployment pipelines)
WPBeginner nói rất đúng4: “Hầu hết WordPress users không cần headless. Nó đắt đỏ, phức tạp không cần thiết, và không phù hợp cho đại đa số website, bloggers, doanh nghiệp nhỏ, hay online stores.” Mình đồng ý, headless phù hợp với developer hoặc team có developer – không phải cho người dùng WordPress để… dùng WordPress, mà để phục vụ một số yêu cầu cụ thể.
5. Một số plugin vẫn hoạt động, một số thì không
Mình có 2 tin tốt và xấu, bạn muốn nghe cái nào 😁.
Tin tốt là một số plugin phổ biến quan trọng đều hỗ trợ: Rank Math SEO hỗ trợ tốt GraphQL với plugin WPGraphQL for Rank Math SEO (meta tags, Open Graph, JSON-LD data). Advanced Custom Fields có plugin WPGraphQL for ACF. WooCommerce có WPGraphQL WooCommerce extension (nhưng phức tạp), WPML cũng hỗ trợ WPGraphQL rất đầy đủ (azdigi.com/blog đang dùng). Yoast SEO cũng hoạt động qua REST API từ version 14.0.
Tin xấu: Bất kỳ plugin nào cần render ra bên ngoài hoặc render ra với HTML (page builders, form plugins, popup plugins, slider plugins) đều không hoạt động. Plugin nào chỉ xử lý backend logic (custom post types, custom fields, SEO data) thì vẫn dùng tốt.
Vì vậy khi sử dụng WordPress headless, bạn cần biết chính xác website mình sẽ phụ thuộc vào plugin nào để có quyết định đúng đắn.
6. Gutenberg – dùng được nhưng không What You See Is What You Get (WYSIWYG)
Bạn vẫn dùng Gutenberg editor để viết bài. Nhưng output là HTML thuần, các tính năng liên quan đến layout như chia cột, các block liên quan đến render ra bên ngoài. Bạn nhìn thấy heading, paragraph, hình ảnh trong editor, nhưng style sẽ khác hoàn toàn so với frontend.
Bản chất Gutenberg khi xuất nội dung ra thông qua WPGraphQL là cấu trúc HTML, nếu bạn muốn frontend hỗ trợ block nào thì chỉ cần xem cấu trúc HTML của nó ngoài trang bài viết ở frontend rồi nhờ AI bổ sung CSS/Javascript để nó hoạt động theo mong muốn.
Nếu bạn muốn frontend hỗ trợ Gutenberg tốt hơn thì có thể sử dụng plugin WPGraphQL Gutenberg
WPGraphQL Gutenberg hoạt động thế nào?
Mặc định khi bạn lấy nội dung bài viết, phần content sẽ hiển thị output là HTML đã được render:
query GetPost {
post(id: "hello-world", idType: SLUG) {
title
content # → "<p>Hello world</p><figure class='wp-block-image'>..."
}
}Nhưng khi sử dụng thêm plugin WPGraphQL Gutenberg, bạn có thể cho WPGraphQL gửi về nội dung có cấu trúc theo từng block:
query GetPost {
post(id: "hello-world", idType: SLUG) {
title
blocks {
name # "core/paragraph"
__typename # "CoreParagraphBlock"
attributes {
content # "Hello world"
align # "left"
textColor # "primary"
}
innerBlocks { # Nested blocks (columns, groups...)
name
attributes { ... }
}
}
}
}Ví dụ trong bài viết bạn có tinh chỉnh màu sắc cho block nào đó, thì dữ liệu trả về chứa đầy đủ để bạn có thể cho frontend tuỳ biến lại mà hiển thị chính xác màu đó (trường hợp ví dụ trên là màu có tên primary
Bạn có thể khai báo sẵn để frontend render toàn bộ block và tách theo từng component, muốn dùng cái gì thì import vào là được.
Xem chi tiết tài liệu WPGraphQL Gutenberg
Cá nhân mình thì không sử dụng WPGraphQL Gutenberg vì bài viết của mình chỉ sử dụng vài block cơ bản và chỉ cần CSS/JS cho vài block cần thiết thông qua cấu trúc HTML. Nhưng với các website đặc biệt là dạng landing page/trang dịch vụ sử dụng Block Editor để dàn trang với cách sử dụng block phức tạp thì cân nhắc sử dụng phương án WPGraphQL Gutenberg như ở trên.
7. SEO – tự chịu trách nhiệm hoàn toàn
Với WordPress truyền thống, cài Yoast hoặc Rank Math thì SEO được xử lý gần như tự động: meta tags, Open Graph, sitemap.xml, robots.txt, schema markup, plugin lo hết. Thậm chí nó còn dễ dàng đến nổi nhiều người lầm tưởng WordPress tốt cho SEO nhưng thực tế chính các plugin này mới giúp trang của họ thân thiện với SEO hơn và tuỳ chỉnh SEO tốt hơn.
Chuyển sang headless, bạn cần phải viết code để đảm bảo các dữ liệu đó hiển thị ở frontend (nếu plugin có hỗ trợ, đọc lại tin vui ở phần trên). Plugin vẫn lưu data (meta description, focus keyword, schema settings) ở backend, nhưng không còn ai render chúng ra <head> của trang web nữa. Bạn phải tự làm.
Cách mình xử lý:
- Meta tags: Rank Math cung cấp đầy đủ dữ liệu SEO WPGraphQL — title, description, Open Graph, Twitter Cards. Mình query data này rồi chèn vào
<head>ở Astro layout. Toàn quyền kiểm soát, muốn thêm gì bỏ gì tuỳ ý. Để chắc ăn hơn mình có cơ chế tự fallback lấy tiêu đề bài viết làm title và một đoạn nội dung đầu tiên làm description nếu Rank Math không hoạt động vì lý do nào đó. - Sitemap: Bạn phải tự viết code để tạo XML sitemap cho trang để submit lên Google. Nhưng mình có một ý tưởng hay hơn đó là viết một route ở frontend cho link /sitemap-index.xml và proxy thẳng đến sitemap của backend tạo ra bởi Rank Math SEO, với điều kiện là frontend phải truy cập được file sitemap ở backend.
- JSON-LD Schema: Tự viết template cho từng loại page (Article, BreadcrumbList, WebSite). Nghe tốn công nhưng thực tế template viết một lần dùng mãi, và bạn kiểm soát được chính xác Google nhận được structured data gì, không phải đoán xem plugin output cái gì. Rank Math cũng hỗ trợ truyền thông tin này ra frontend và bạn có thể parse ra dùng nếu muốn.
- Canonical URLs, hreflang, robots meta: May mắn là Rank Math SEO cũng trả về các thông tin này nên chỉ cần chèn data vào
<head>là được
Thực tế: SEO trên headless tốn công setup ban đầu nhưng sau đó cho bạn mức kiểm soát mà WordPress truyền thống không bao giờ đạt được. Muốn A/B test meta description? Dễ. Muốn custom schema cho từng category? Dễ. Muốn tự thêm FAQ schema cho bài nào có FAQ? Chỉ cần viết code với cơ chế tự nhận diện, không cần plugin nào.
8. Hệ thống bình luận – phải tự chọn giải pháp
Tính năng bình luận trong WordPress không hoạt động vì frontend không còn render qua PHP. Bạn cần tìm giải pháp thay thế.
Các lựa chọn phổ biến:
- Giscus (GitHub Discussions-based): Mình chọn cái này cho thachpham.com. Ưu điểm: không cần database riêng, hỗ trợ Markdown, reactions, threading. Nhược điểm: người comment cần tài khoản GitHub phù hợp cho blog kỹ thuật, không phù hợp cho blog lifestyle.
- Disqus, Hyvor Talk: Dịch vụ thứ ba (có trả phí), dễ nhúng, có trang quản lý. Nhược điểm: tốn tiền.
- WordPress Comments qua API: Vẫn có thể dùng WordPress REST API để post/get comments. Cần build UI bình luận ở frontend và có hướng xử lý anti-spam và bảo mật (reCAPTCHA, chặn bot,…). Phức tạp nhất nhưng giữ được comments trong WordPress database.
Cách mình xử lý: Giscus được nhúng dưới dạng Svelte component với client:visible trong Astro, nghĩa là component chỉ load khi độc giả cuộn trang đến phần comments, không ảnh hưởng đến tốc độ tải trang ban đầu.
9. Tính năng tìm kiếm – Mất mát nhưng cũng là cơ hội
Mình gọi là cơ hội vì khi dùng headless, bạn phải tự triển khai tính năng tìm kiếm nội dung trên trang nhưng chính điều này là điềm lành vì…
WordPress có tính năng tìm kiếm thực ra khá tệ, nó chỉ chạy LIKE %keyword% query trên database, không hỗ trợ xếp hạng mức độ liên quan, không tìm kiếm full-text, và đặc biệt tệ với tiếng Việt. Nhưng ít nhất nó có sẵn. Với headless, bạn không có cái “tệ sẵn” đó, đáng mừng mà 😄.
Các lựa chọn thay thế bao gồm:
- ElasticPress + Elasticsearch: Mình chọn cái này. Full-text search hỗ trợ tiếng Việt, relevance ranking tốt, và bonus lớn: thuật toán More Like This giúp mình tận dụng tính năng hiển thị bài liên quan load cực nhanh (chỉ 3ms cho 1 query) và chính xác. Nhược điểm: cần tự host Elasticsearch, có thể dùng ElasticPress Cloud nhưng chi phí khá chát.
- Algolia: Search-as-a-service, cực nhanh, UI components có sẵn. Nhược điểm: có phí, data ở bên thứ ba.
- WordPress REST API search: Dùng endpoint
/wp/v2/search. Đơn giản nhất nhưng chất lượng search kém và mỗi search query đều đấm thẳng vô mặt backend. - Pagefind: Static search index generate tại build time. Miễn phí, không cần server, rất nhanh. Phù hợp cho site nhỏ-trung. Nhưng không phù hợp với thachpham.com vì nội dung đều là Server-side rendering.
Cách mình xử lý: ElasticPress sync data từ WordPress sang Elasticsearch. Frontend gọi Elasticsearch trực tiếp (qua proxy endpoint và Elasticsearch chạy trong mạng private). Mỗi lần tìm kiếm chỉ mất khoảng 100ms cho mọi query, một trang WordPress thường không bao giờ có tốc độ tìm nhanh như vậy, không tin sao? Hãy ấm cmd + K hoặc nút search ở đầu blog mình và tìm thử bất kỳ từ khoá nào.
10. Caching – tưởng dễ, hoá ra cũng khó
Với WordPress truyền thống, caching gần như là chuyện “cài plugin rồi quên đi.”, WP Super Cache, W3 Total Cache, hay WP Rocket bật lên, chọn vài settings, xong. Plugin lo toàn bộ từ page cache, object cache, browser cache, cache purge khi publish bài mới. Bạn không cần biết cache key là gì, TTL là gì, invalidation strategy là gì.
Chuyển sang headless, bạn mất tất cả những thứ đó. Và đây không phải thách thức kiểu “tìm plugin thay thế”, đây là thách thức về mặt kiến trúc, đòi hỏi bạn phải thiết kế cả một hệ thống caching từ đầu.
Vấn đề cốt lõi là thế này: Frontend headless gọi dữ liệu từ WordPress qua API (GraphQL hoặc REST). Mỗi request của user → frontend gọi API → WordPress query database → trả JSON → frontend render HTML. Nếu không có cache, mỗi lượt truy cập đều phải đi hết chuỗi đó. Với blog vài trăm lượt/ngày thì không sao, nhưng scale lên vài ngàn lượt thì WordPress backend sẽ trở thành cái cổ chai to đùng bị thắt chặt, đau lòng hơn khi đây chính xác là cái vấn đề mà bạn đang cố thoát khỏi khi chuyển sang headless.
Và khi bạn bắt đầu thêm cache, một câu hỏi khó hơn xuất hiện: khi nào thì xóa cache? Bạn đăng bài mới → cache trang chủ phải được xóa vì danh sách bài mới đã thay đổi. Bạn cập nhật bài cũ → bộ nhớ đệm của riêng bài đó phải xóa, nhưng cache trang chủ có thể vẫn giữ (trừ khi title hoặc excerpt thay đổi). Bạn thêm bài vào category → cache của category đó phải xóa. Nghe đơn giản trên giấy, nhưng triển khai thực tế thì có rất nhiều vấn đề hóc búa, lắt léo (từ giờ mình sẽ dùng từ edge case để mô tả ý này) xuất hiện.
Cách mình xử lý cho thachpham.com: kiến trúc caching nhiều tầng:
Thay vì dựa vào một lớp cache duy nhất, mình xây dựng hệ thống caching hai tầng chính, mỗi tầng có vai trò riêng biệt:
Thông tin thêm: Nếu bạn sử dụng cơ chế SSG thì không cần quan tâm cache làm gì vì nội dung sau khi build đã là file tĩnh, trả về gần như tức thì. Chỉ cần quan tâm nếu áp dụng SSR hoặc Hybrid giống mình.
Tầng ngoài cùng: Cloudflare CDN – chặn request trước khi nó đến server
Đây là tầng quan trọng nhất và cũng là tầng mà đa số người dùng thực sự interact. Cloudflare cache HTML response ngay tại edge server gần user nhất, user ở Hà Nội hit edge server ở Hongkong, user ở TP.HCM hit edge server ở Singapore. Các truy cập không bao giờ cần đi về origin server. Đây là lý do TTFB đạt ~80ms cho phần lớn requests – đó là latency đến Cloudflare edge, không phải đến server mình.
Nhưng vấn đề lớn nhất của Cloudflare cache trong kiến trúc headless: làm sao xoá cache đúng URL khi nội dung thay đổi trên WordPress? WordPress và Cloudflare là hai hệ thống hoàn toàn tách biệt – WordPress không biết Cloudflare đang cache những URL nào, và Cloudflare không biết khi nào WordPress có bài mới.
Mình phải tự viết một plugin WordPress riêng để giải quyết chuyện này. Khi bạn đăng mới hoặc cập nhật bài trên WordPress, plugin sẽ tự động gọi Cloudflare API để xoá cache cho đúng những URL bị ảnh hưởng: URL của bài viết đó, trang chủ, trang category mà bài thuộc về, sitemap. Không purge toàn bộ cache (quá tốn), chỉ purge đúng những gì thay đổi. Plugin này nghe đơn giản nhưng tốn kha khá thời gian để xử lý các edge case: bài chuyển category thì phải xoá cả category cũ lẫn mới, bài từ draft chuyển sang publish thì phải xoá trang chủ và lưu trữ, bài bị xóa thì phải xoá khác với bài bị update.
Tầng trong: Redis — cache API response ngắn hạn theo mô hình BFF
Vì đã có Cloudflare ở tầng ngoài lo chuyện cache dài hạn cho end user, Redis ở tầng trong không cần lưu cache lâu. Vai trò của Redis ở đây là cache kết quả GraphQL query để giảm tải cho WordPress backend — đặc biệt quan trọng khi Cloudflare cache miss (URL chưa được cache, hoặc vừa bị purge).
Mình xây dựng lớp Redis cache theo mô hình BFF (Backend for Frontend) — một lớp trung gian nằm giữa frontend Astro và WordPress GraphQL API.
Luồng hoạt động đầy đủ:
User → Cloudflare Edge (tầng 1) → Astro SSR → BFF Layer → Redis Cache (tầng 2) → WPGraphQL
Khi Cloudflare cache hit, request dừng ngay ở tầng 1 — user nhận response trong ~80ms. Khi Cloudflare cache miss (sau purge hoặc URL mới), request đi đến origin, BFF layer kiểm tra Redis — nếu có thì trả ngay (200-300ms), nếu không thì mới gọi GraphQL, lưu kết quả vào Redis rồi trả về.
TTL strategy — tại sao 5 phút là đủ?
Vì Cloudflare đã là tầng cache chính với TTL dài hơn, Redis chỉ đóng vai trò đệm ngắn hạn để bảo vệ WordPress backend khỏi bị gọi liên tục. TTL 5 phút cho response cache (dữ liệu bài viết, danh sách bài) là hợp lý vì hai lý do: một là blog cá nhân ít khi update bài liên tục (mình publish 2-3 bài/tuần, sửa bài cũ thì còn hiếm hơn), hai là khi content thực sự thay đổi thì webhook + Cloudflare purge plugin đã xử lý invalidation chủ động rồi — không cần đợi TTL hết hạn. Cursor cache (dữ liệu phân trang) set 30 phút vì gần như không bao giờ thay đổi giữa các lần publish.
Nói cách khác: TTL ở đây không phải cơ chế invalidation chính — webhook mới là. TTL chỉ là safety net, đảm bảo rằng nếu webhook fail vì lý do nào đó, data cũng chỉ stale tối đa 5 phút.
Cache invalidation — phần phức tạp nhất:
Mình dùng webhook từ WordPress để trigger invalidation ở cả hai tầng. Khi có thay đổi content trên WordPress (publish, update, delete), hai việc xảy ra song song: plugin Cloudflare purge xóa cache ở CDN edge, và webhook gửi đến endpoint /api/webhook/wordpress trên frontend để xóa cache Redis tương ứng.
Logic invalidation ở Redis chia làm hai cấp:
- Post updated (sửa bài đã publish): Xóa cache của chính bài đó (
post:{slug}), xóa cache của các categories mà bài thuộc về, và xóa cache trang 1 của archive. - Post created hoặc deleted (thêm hoặc xóa bài): Xóa tất cả những thứ trên, cộng thêm toàn bộ response pages cache, cursor cache, và post count cache — vì tổng số bài đã thay đổi, phân trang bị ảnh hưởng.
Pattern invalidation dùng lệnh SCAN của Redis thay vì KEYS — KEYS * sẽ block Redis khi có nhiều keys, còn SCAN iterate non-blocking nên không ảnh hưởng performance.
Graceful degradation – chuyện gì xảy ra khi Redis chết?
Graceful degradation nếu dịch ra tiếng Việt thì nghe khá khó hiểu như “Sự suy giảm chức năng có kiểm soát”, nhưng có thể hiểu nôm na là sự tương thích ngược nếu một vấn đề xảy ra. Vì vậy bài viết này mình sẽ giữ nguyên từ này vì đây là thuật ngữ chuyên ngành.
Nếu Redis server down, website không được chết theo. Giải pháp: implement memory fallback — khi Redis connection fail, hệ thống tự động chuyển sang in-memory cache trên Node.js process. Performance giảm (memory cache không share được giữa các process, capacity nhỏ hơn), nhưng website vẫn hoạt động bình thường vì Cloudflare edge cache vẫn đang serve phần lớn requests. Khi Redis recover, hệ thống tự reconnect và chuyển lại. Đây cũng là lợi ích của kiến trúc nhiều tầng — một tầng chết thì tầng khác vẫn giữ được.
Cache versioning — bảo hiểm cho deployment
Đây là edge case mình nhận ra khá trễ khi deploy dự án lên production.
Sau khi deploy code mới, logic transform dữ liệu có thể thay đổi (thêm field mới, đổi format). Nhưng Redis vẫn giữ data theo format cũ → frontend nhận data sai → lỗi. Giải pháp: mỗi cache key được gắn một số phiên bản do bạn quy định. Khi transform logic thay đổi, bump version → cache cũ tự động miss → data mới được fetch và cache lại. Không cần flush toàn bộ Redis.
Stale-while-revalidate – trả data cũ ngay, fetch data mới ở background
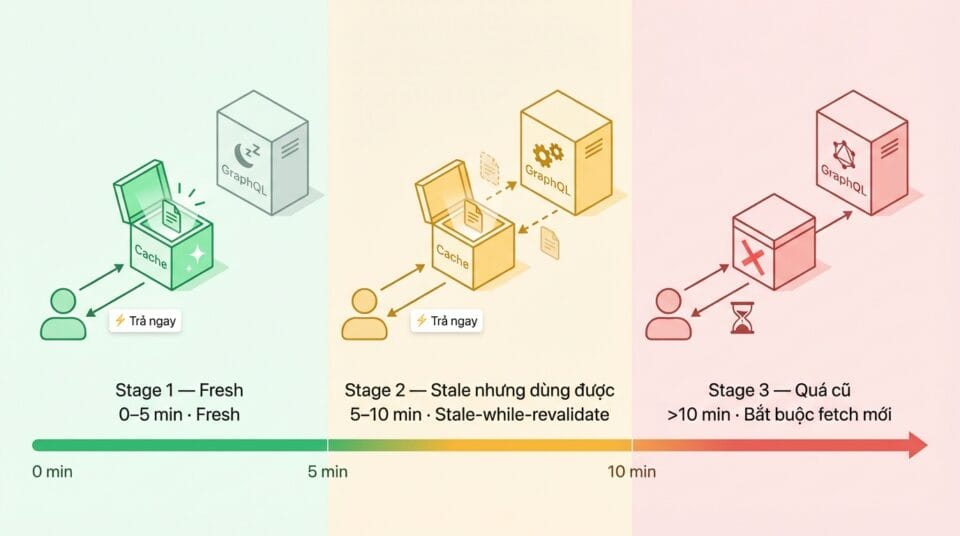
Caching thông thường hoạt động kiểu yes/no: cache còn hạn → trả ngay, cache hết hạn → fetch mới rồi mới trả. Vấn đề là ở giây phút cache vừa hết hạn, user đầu tiên truy cập phải đợi 200-500ms để hệ thống gọi GraphQL, nhận response, lưu cache, rồi mới trả về. User đó chịu “đau khổ”, trong khi data cũ (mới hết hạn cách đó vài giây) thực ra vẫn hoàn toàn dùng được, blog post mà, không phải giá meme coin.
Stale-while-revalidate giải quyết chuyện này bằng cách thêm grace period — một khoảng thời gian sau khi TTL hết hạn mà data cũ vẫn được phép serve. Khi triển khai trên azdigi.com, mình set grace period = 2x TTL: cache TTL mặc định 5 phút (fresh), grace period 10 phút (stale nhưng dùng được), sau 10 phút mới thực sự bắt buộc fetch mới.
Nếu bạn không dùng edge caching ở CloudFlare, thì có thể đặt grace period lên cực cao nhưng cẩn thận sẽ tốn bộ nhớ Redis nhé.
Luồng hoạt động thực tế:
- Request đến, cache còn trong 5 phút đầu → trả ngay, không làm gì thêm.
- Request đến, cache đã qua 5 phút nhưng chưa đến 10 phút → trả data cũ ngay lập tức (user nhận phản hồi tức thì), đồng thời kích hoạt một lần fetch GraphQL ở background. Khi fetch xong, cache được cập nhật lặng lẽ. User tiếp theo sẽ nhận data mới.
- Request đến, cache đã quá 10 phút → data quá cũ, bắt buộc fetch mới trước khi trả.
Một chi tiết triển khai mà mình mất thời gian debug: phải loại bỏ sự trùng lặp trong quá trình tạo cache Nếu 10 requests đến cùng lúc khi cache đang stale, cả 10 đều trigger background refresh → 10 requests gọi GraphQL. Giải pháp là dùng một Set lưu các key đang được revalidate, nếu key đã nằm trong Set, skip luôn, không gọi API thêm:
const revalidating = new Set<string>();
function revalidateInBackground<T>(
key: string,
fetcher: () => Promise<T>,
ttl: number
): void {
if (revalidating.has(key)) return; // Đã có process khác đang refresh
revalidating.add(key);
fetcher()
.then(data => cache.set(key, { data, timestamp: Date.now() }, ttl))
.catch(() => { /* Giữ stale data nếu fetch fail */ })
.finally(() => revalidating.delete(key));
}Kết quả thực tế trên azdigi.com: TTFB giảm đến 600ms tại thời điểm cache hết hạn. User không bao giờ phải đợi refresh. Và nếu background fetch lỗi (WordPress down, network timeout), user vẫn nhận stale data thay vì trang lỗi, graceful degradation tự nhiên mà không cần code thêm logic xử lý lỗi phức tạp.
Với thachpham.com, mình chưa triển khai vì chưa cần thiết, 200ms khi cache miss chưa phải vấn đề đáng lo. Nhưng nếu bạn build headless cho site có traffic đáng kể hoặc site thương mại, đây nên là tính năng nên tính toán từ sớm.
Cache warming – tạo sẵn cache cho user thật (hay có thể gọi là Preload)
Sau mỗi lần deploy thay đổi trên code, hoặc sau khi Redis restart, toàn bộ cache trống rỗng. User đầu tiên truy cập bất kỳ trang nào đều chịu cold start – phải đợi GraphQL fetch, Elasticsearch query, cursor resolution,… tất cả từ đầu. Nếu site bạn có traffic cực lớn, cú cold start này nhiều khi làm sập server của cả hệ thống là chuyện bình thường.
Tính năng này có thể mở rộng ra để preload toàn bộ nội dung dựa theo sitemap giống WP Rocket, nhưng mình triển khai trên trang azdigi.com chọn phương án warming từ từ và số lượng ít có kiểm soát vì thực ra traffic chỉ tập trung tại 1 số page quan trọng.
Giải pháp: chủ động tạo sẵn cache ngay khi hệ thống khởi động, trước khi user thật bắt đầu truy cập.
Trên azdigi.com, mình triển khai cache warming theo hai cơ chế:
Warming khi deploy: Cuối pipeline CI/CD (GitHub Actions), sau khi deploy xong và health check pass, chạy một warm-up script tự động request các trang quan trọng nhất: trang chủ blog, 20 pages đầu tiên của archive (vì 80% traffic tập trung ở đây), các category pages chính. Khi user thật đầu tiên truy cập, mọi thứ đã sẵn sàng.
Warming khi cache miss: Khi user truy cập page 1 mà cursor cache trống (ví dụ sau khi TTL 30 phút hết hạn), BFF không chỉ fetch page 1 — nó trigger background warming cho 20 pages đầu. Logic: nếu ai đó đang đọc page 1 thì khả năng cao sẽ click page 2, 3, 4. Warm sẵn để khi họ click, response gần như tức thì.
// Trigger background warming khi user truy cập page đầu
for (let page = 1; page <= WARM_PAGES; page++) {
const cursor = await fetchCursorForPage(page);
cursorCache.set(`vi:all:all:per:12:page:${page}`, cursor);
}Tại sao 20 pages? Quy tắc 80/20 – 80% traffic vào 20 pages đầu. Warm thêm cũng được nhưng tốn thời gian khởi động và GraphQL requests. Con số này configurable qua environment variable BLOG_CACHE_WARM_PAGES, mình thường điều chỉnh dựa trên thống kê.
Kết quả: page load trang chủ từ 4,028ms (cold, không cache gì cả) xuống 378ms (warm nhưng chưa cached lần truy cập đầu) xuống <10ms (cached). User thật gần như không bao giờ chạm vào cold start nữa.
Với thachpham.com, mình dùng cơ chế đơn giản hơn: WordPress webhook trigger khi publish bài → xóa cache liên quan → Cloudflare purge plugin xóa CDN cache → request đầu tiên sau purge tự warm lại. Không cần warm-up script riêng vì blog cá nhân có traffic thấp, cold start 200-300ms chấp nhận được. Nhưng nếu bạn build headless cho site mà cold start 4 giây là vấn đề (và hầu hết production site đều vậy), cache warming nên nằm trong deployment pipeline từ đầu.
Request coalescing — 1000 requests, chỉ 1 lần gọi API
Bạn đăng bài mới tinh, share lên Facebook group 50 ngàn thành viên. 500 người click vào link trong vòng 2 giây. Đúng lúc đó, cache trang chủ vừa hết hạn. Đoán xem chuyện gì sẽ xảy ra?
Không có request coalescing: 500 requests đến frontend → 500 lần thấy cache trống → 500 requests gọi WordPress GraphQL API cùng lúc → WordPress server quá tải → trả về 503 → tất cả users thấy lỗi. Đây là hiệu ứng quá tải đồng thời (thundering herd problem), và nó sẽ xảy ra chính xác khi website bạn đang ở trạng thái đỉnh cao nhất: ĐÔNG NGƯỜI TRUY CẬP.
Với request coalescing: Request đầu tiên gọi GraphQL API. 499 requests còn lại đợi cùng một Promise thay vì mỗi request gọi API riêng. Khi request đầu tiên nhận response, tất cả 499 requests đều nhận kết quả từ cùng một lần gọi đó. WordPress chỉ nhận 1 request thay vì 500.
Triển khai tính năng này trên azdigi.com đơn giản đến bất ngờ khi chỉ cần 10 dòng code:
const pending = new Map<string, Promise<unknown>>();
function withCoalescing<T>(key: string, fetcher: () => Promise<T>): Promise<T> {
if (!pending.has(key)) {
const promise = fetcher().finally(() => pending.delete(key));
pending.set(key, promise);
}
return pending.get(key) as Promise<T>;
}
// Sử dụng:
// Trước: mỗi request gọi API riêng
const posts = await fetchPosts({ page: 1 });
// Sau: tất cả concurrent requests share cùng một lần gọi
const posts = await withCoalescing('posts:vi:page:1', () => fetchPosts({ page: 1 }));Map lưu các Promise đang pending. Request mới đến → check Map → nếu đã có Promise cho key đó (nghĩa là có request tương tự đang chạy) → trả về cùng Promise đó. Khi Promise đã xử lý hoặc từ chối, finally block tự xóa khỏi Map → request tiếp theo sẽ tạo Promise mới. Khi không có concurrent requests, Map trống, code chạy bình thường.
Kết quả trên azdigi.com: giảm 60% tải cho WordPress API trong điều kiện traffic bình thường, và ngăn được server overload hoàn toàn khi traffic đột biến.
Nhưng có một edge case: azdigi.com chạy PM2 cluster mode (nhiều Node.js processes). Mỗi process có Map riêng → coalescing chỉ hoạt động trong cùng một process. 4 processes = tệ nhất vẫn 4 requests thay vì 1. Giải pháp mình dùng thêm: distributed locking với Redis SETNX cho tác vụ cache warming. Trước khi warming, process gọi SETNX lock:warm:vi 1 TTL=30 — chỉ process đầu tiên nhận true và tiến hành warming, các processes khác đợi kết quả. SETNX là atomic operation, TTL tự hết hạn nếu process crash, không deadlock.
Với thachpham.com chạy single process, request coalescing đơn giản là đủ. Distributed locking là overkill cho blog cá nhân. Nhưng nếu site của bạn chạy multi-process hoặc serverless (mỗi invocation là process riêng), distributed locking trở thành bắt buộc, không phải tùy chọn.
Content-hash invalidation — chỉ cập nhật cache khi content thực sự thay đổi
Caching truyền thống hoạt động theo thời gian: TTL 5 phút, hết 5 phút thì xóa cache, fetch lại từ đầu. Nhưng thực tế thì sao? Blog post mình viết xong, publish lên, rồi có khi cả tháng không sửa lại. Vậy mà cứ 5 phút cache lại hết hạn → fetch lại GraphQL → nhận đúng cái data y hệt → lưu lại vào cache. Lặp đi lặp lại 288 lần/ngày cho mỗi bài, nghe có vẻ hơi vô tri (mặc dù trước nó là lớp cache ở CloudFlare mình lưu TTL tận 30 ngày).
Ý tưởng đơn giản: hash nội dung response. Khi lưu cache, hash luôn data (mình dùng MD5 vì tiện, không cần cryptographic security ở đây). Khi đến lúc revalidate (stale-while-revalidate trigger background fetch), fetch data mới từ GraphQL → hash → so sánh với hash cũ. Nếu giống nhau thì content không thay đổi mà chỉ renew TTL mà không cần parse, transform, hay ghi lại cache. Nếu khác → content thực sự thay đổi → cập nhật cache bình thường.
async function revalidateWithHash<T>(
key: string,
fetcher: () => Promise<T>,
ttl: number
): Promise<void> {
const newData = await fetcher();
const newHash = md5(JSON.stringify(newData));
const existing = await cache.get(key);
if (existing && existing.hash === newHash) {
// Content không đổi — chỉ gia hạn TTL
await cache.touch(key, ttl);
return;
}
// Content thực sự thay đổi — cập nhật cache
await cache.set(key, { data: newData, hash: newHash, timestamp: Date.now() }, ttl);
}Kết hợp với stale-while-revalidate, flow đầy đủ trở thành:
- Cache hết TTL 5 phút → trả stale data ngay cho user (instant response).
- Background: fetch data mới từ GraphQL → hash → so sánh.
- 95% trường hợp: hash giống →
touchgia hạn TTL → xong. Không parse JSON nặng, không ghi Redis, không transform data. - 5% trường hợp: hash khác → cập nhật cache đầy đủ.
Con số 95% không phải mình bịa ra đâu, blog với tần suất publish 2-3 bài/tuần, 2000+ bài trong database, tại bất kỳ thời điểm nào thì tỷ lệ bài đang được sửa so với tổng số bài là cực kỳ nhỏ. Phần lớn quá trình kiểm tra cache đều kết thúc bằng “à, không có gì thay đổi.”
Lợi ích quá rõ ràng rồi, giảm đáng kể write operations lên Redis (ít I/O hơn, Redis bền hơn), giảm CPU cho JSON parsing và data transformation ở những lần revalidate không cần thiết, và quan trọng nhất – khi kết hợp với stale-while-revalidate thì user gần như không bao giờ chịu cache miss penalty nữa. Data cũ được serve tức thì, background check xác nhận “không có gì mới” rồi gia hạn, chu kỳ lặp lại.
Một chi tiết nhỏ nhưng đáng lưu ý: mình hash sau khi fetch nhưng trước khi transform. Nếu hash sau transform, mỗi lần bạn deploy code mới có thay đổi transform logic (thêm field, đổi format), hash sẽ khác dù raw data giống nhau → cache bị invalidate không cần thiết. Hash raw response từ GraphQL thì ổn định hơn khi chỉ thay đổi khi content thực sự thay đổi trên WordPress.
Kết hợp cả ba – pipeline hoàn chỉnh và những lưu ý khi triển khai
Ba tính năng trên không hoạt động độc lập mà tạo thành một pipeline theo thứ tự rõ ràng: coalescing ở tầng network (gom request) → stale-while-revalidate ở tầng cache policy (quyết định khi nào fetch) → content-hash ở tầng write optimization (quyết định có cần ghi cache không). Khi triển khai trên azdigi.com, mình nối chúng lại như sau:
// Pipeline hoàn chỉnh: coalescing → stale-while-revalidate → content-hash
async function fetchWithFullPipeline<T>(
key: string,
fetcher: () => Promise<T>,
ttl: number,
gracePeriod: number
): Promise<T> {
const cached = await cache.get(key);
const age = cached ? Date.now() - cached.timestamp : Infinity;
// Giai đoạn 1: Cache fresh → trả ngay
if (cached && age < ttl) {
return cached.data;
}
// Giai đoạn 2: Cache stale nhưng trong grace period → trả stale, revalidate background
if (cached && age < ttl + gracePeriod) {
// Background revalidate đi qua coalescing → chỉ 1 request gọi API
revalidateInBackground(key, () => withCoalescing(key, fetcher), ttl);
return cached.data;
}
// Giai đoạn 3: Cache quá cũ → bắt buộc fetch, nhưng vẫn qua coalescing
const freshData = await withCoalescing(key, fetcher);
const hash = md5(JSON.stringify(freshData));
await cache.set(key, { data: freshData, hash, timestamp: Date.now() }, ttl + gracePeriod);
return freshData;
}Bạn sẽ thấy withCoalescing wrap bên ngoài fetcher ở cả giai đoạn 2 (background revalidate) và giai đoạn 3 (forced fetch). Điều này đảm bảo dù 500 requests đến cùng lúc khi cache quá cũ, chỉ 1 request gọi API thật sự. Và revalidateInBackground bên trong sẽ gọi content-hash check trước khi quyết định ghi cache.
Vài lưu ý mình rút ra sau khi triển khai thực tế:
Đừng để hai lớp dedup chồng nhau mà không biết. Ban đầu mình có revalidating Set (từ stale-while-revalidate) chặn trùng lặp ở tầng cache, đồng thời pending Map (từ coalescing) chặn trùng lặp ở tầng fetch. Cả hai đều ngăn gọi API trùng, nhưng ở hai tầng khác nhau. Nếu để tách rời, code vẫn chạy đúng nhưng bạn sẽ khó debug khi có vấn đề vì không biết request bị chặn ở tầng nào. Cách gọn nhất là để coalescing xử lý trùng lặp ở tầng fetch (nó làm tốt nhất việc này), còn stale-while-revalidate chỉ lo quyết định khi nào cần gọi fetch, không cần revalidating Set riêng nữa.
Hash phải tính trên raw response, trước khi coalescing share data. Coalescing trả về data cho tất cả requests đang đợi, nhưng nếu bạn transform data sau khi nhận từ coalescing rồi mới hash, mỗi lần đổi transform logic là hash khác → cache invalidate vô ích. Đặt bước hash bên trong fetcher, ngay sau khi nhận raw response từ GraphQL, trước khi transform, thì hash ổn định theo content thực sự chứ không theo code logic.
Xử lý background fetch fail. Đây là edge case dễ bỏ qua. Nếu background fetch fail trong stale-while-revalidate (WordPress down, network timeout), content-hash không có data mới để so sánh. Lúc này mình gia hạn TTL stale data thêm một chu kỳ ngắn (1 phút thay vì 5 phút bình thường) để hệ thống retry sớm hơn. Nếu không xử lý, cache sẽ hết grace period → rơi vào giai đoạn “quá cũ” → user bắt đầu chịu cold fetch → đúng lúc WordPress vẫn đang down → lỗi cho tất cả. Gia hạn ngắn giữ stale data sống thêm trong khi chờ WordPress phục hồi, graceful degradation thực sự.
// Trong revalidateInBackground — xử lý fetch fail
fetcher()
.then(newData => {
const newHash = md5(JSON.stringify(newData));
const existing = cache.get(key);
if (existing?.hash === newHash) {
cache.touch(key, ttl); // Content không đổi → gia hạn bình thường
} else {
cache.set(key, { data: newData, hash: newHash, timestamp: Date.now() }, ttl);
}
})
.catch(() => {
// Fetch fail → gia hạn stale data thêm 1 phút để retry sớm
cache.touch(key, 60_000);
});Kết quả thực tế:
Với kiến trúc hai tầng Cloudflare + Redis, đa số requests được serve từ Cloudflare edge (~80ms, hoặc 300ms trong các lúc mạng Việt Nam đi quốc tế chậm). Requests đi đến server được Redis đỡ (~200ms cache hit). Chỉ khi cả hai tầng đều miss thì mới gọi GraphQL (~700ms đến vài giây). WordPress backend gần như không chịu tải trực tiếp từ người dùng, nên có thể chạy trên server cấu hình vừa phải mà vẫn mượt, đây là lợi ích lớn nhất của kiến trúc caching nhiều tầng trong headless.
Lời khuyên: Nếu bạn mới bắt đầu với headless và site chưa có traffic lớn, không cần build phức tạp ngay. Bắt đầu với Cloudflare free plan (có cache cơ bản) + in-memory cache đơn giản ở server. Khi traffic tăng, thêm Redis. Khi cần fine-grained invalidation, viết webhook handler. Đừng cố gắng kỹ thuật quá mức từ đầu, nhưng cũng đừng bỏ qua caching hoàn toàn, vì không có cache thì việc bạn chuyển qua headless vô nghĩa đến 80%.
11. WPGraphQL pagination – cái bẫy 100 bài viết mà không ai nói trước
Đây là thách thức mà bạn sẽ không biết nó tồn tại cho đến khi bạn có đủ nhiều bài viết. Và khi phát hiện ra, thường là trên production và nó sẽ ảnh hưởng đến tính năng phân trang khi có nhiều bài viết.
Câu chuyện thế này: WPGraphQL sử dụng cursor-based pagination5 thay vì offset pagination truyền thống. Thay vì nói “lấy 12 bài từ vị trí 108” (page 10), bạn phải nói “lấy 12 bài sau con trỏ XYZ”. Và con trỏ XYZ đó là cái thứ làm mình hoá điên trong ngày hôm ấy. Muốn có nội dung ở page 9? Phải fetch page 8 trước. Cứ thế cho đến khi hết page.
Nhưng vấn đề thực sự nghiêm trọng hơn: WPGraphQL giới hạn 100 bài mỗi request6. Với blog cá nhân vài chục bài thì không vấn đề gì. Nhưng khi mình build hệ thống blog cho AZDIGI với hơn 2000 bài viết, 12 bài/trang, page 1 đến 8 hoạt động ngon lành, đến page 9 trở đi? Trống trơn. Không có gì cả.
Mình phát hiện bug này khi test phân trang đến trang thứ 11. Nếu phát hiện muộn hơn, giả sử sau khi đã có traffic từ Google thì khả năng user click “trang 10” và thấy trang trắng. Với 2000+ bài, site có hơn 160 trang, mà chỉ 8 trang đầu hiển thị đúng.
Giải pháp: BFF + Cursor Cache. Ở phần trên mình có nói về BFF và Cursor Cache nhưng thực tế tính năng đó sinh ra từ chính cái bug khốn khổ này.
Thay vì frontend gọi trực tiếp WPGraphQL, mình đặt một lớp BFF ở giữa. BFF có nhiệm vụ:
Một, quản lý cursor: Khi user truy cập page 1, BFF fetch dữ liệu và lưu cursor position vào cache. Nhưng quan trọng hơn, BFF trigger một quá trình “warming” ở background — tự động fetch lần lượt từ page 1 đến page 20, lưu hết cursor vào Redis. Khi user click page 10, BFF đã có sẵn cursor → nhảy thẳng đến page 10 mà không cần đi qua page 1-9.
Hai, vượt giới hạn 100 bài: Vì mỗi request chỉ được 100 bài, BFF chia nhỏ thành nhiều request nối tiếp nhau: lấy 100 bài đầu → lấy cursor cuối → dùng cursor đó fetch 100 bài tiếp → lặp lại cho đến khi đủ. Cursor cache lưu kết quả để lần sau không phải fetch lại.
Ba, cache cursor riêng biệt với cache response: Đây là chi tiết quan trọng. Response cache (dữ liệu bài viết) có TTL 5 phút vì content có thể thay đổi. Nhưng cursor cache có TTL 30 phút vì cursor chỉ thay đổi khi có bài mới được thêm hoặc xóa, không phải khi sửa bài. Count cache (tổng số bài để tính phân trang) cũng 30 phút vì lý do tương tự.
Một chi tiết hay mà mình rút ra: cursor phụ thuộc vào page size. Cursor cho perPage=12 khác với perPage=24. Nếu cache key không bao gồm perPage, user đổi page size → pagination sai hoàn toàn. Cache key phải có dạng vi:all:all:per:12:page:9 chứ không phải chỉ vi:page:9.
Kết quả: Page load từ 4,028ms (cold, không cache, lâu vì phải lấy 12 bài) xuống <10ms (cached). Quan trọng hơn, page 10+ từ “không hoạt động” → hoạt động bình thường. Nếu bạn đang build headless cho site có hơn 100 bài (mà hầu hết WordPress site đều vượt con số này sau vài tháng), đây là vấn đề bạn phải giải quyết từ đầu.
12. Bảo mật trên WordPress Headless – mất nhiều hơn bạn tưởng, nhưng được lại cũng nhiều hơn bạn nghĩ
Với WordPress truyền thống, bạn cài Wordfence hoặc All in One Security, bật firewall, set rate limiting, bật xác thực 2 lớp là xong. Plugin lo từ A đến Z: chặn brute force, scan malware, block bad bots, ngăn XSS, thậm chí tự patch virtual vulnerabilities khi có CVE mới nếu dùng hàng xịn. Bạn không cần biết Content Security Policy là gì, không cần biết MIME sniffing attack hoạt động ra sao. Plugin biết cho bạn.
Chuyển sang headless, bạn mất toàn bộ lớp bảo vệ frontend đó. Wordfence vẫn bảo vệ WordPress admin, nhưng admin giờ nằm ở subdomain riêng, không ai truy cập trực tiếp ngoài bạn. Frontend mà hàng ngàn user truy cập mỗi ngày? Hoàn toàn trần trụi. Không firewall plugin, không XSS filter tự động, không rate limiter sẵn có. Bạn phải tự build tất cả.
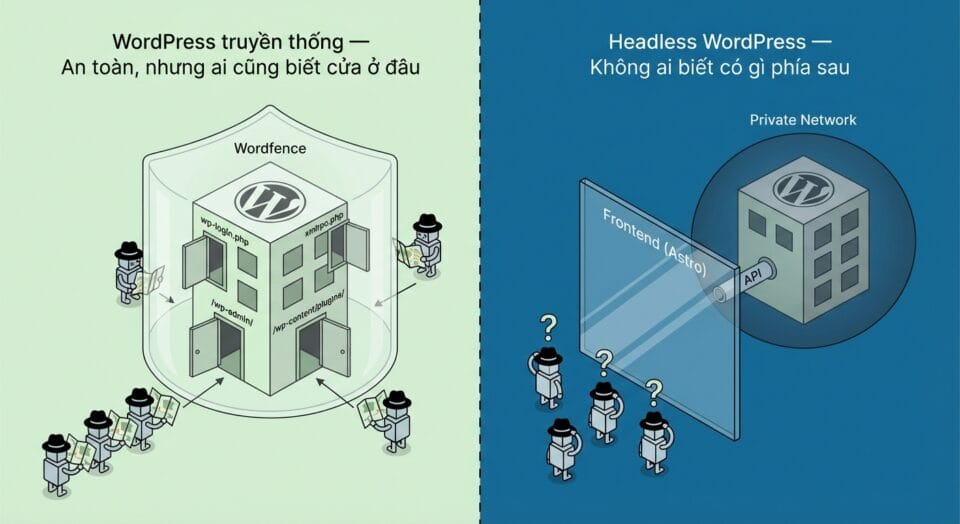
Nghe đáng sợ, nhưng thực ra đây lại là lợi thế nếu bạn nhìn đúng góc. WordPress truyền thống là đối tượng bị dòm ngó lớn nhất internet khi hơn 40% websites chạy WordPress, và attacker biết rõ cấu trúc của nó: wp-login.php để brute force, xmlrpc.php để DDoS, /wp-admin/ để scan, /wp-content/plugins/ để tìm lỗ hổng plugins. Với headless, frontend là Astro/Next.js, attacker không biết bạn đang dùng WordPress ở backend. Không có wp-login.php trên frontend domain. Không có xmlrpc.php. Không có plugin để scan. Rủi ro bị tấn công giảm đáng kể.
Nhưng rủi ro giảm không có nghĩa là bằng không. Dưới đây là những mối lo bảo mật mình phải xử lý khi build headless cho cả thachpham.com và azdigi.com:
1. XSS qua content từ WordPress – nguy hiểm nhất và dễ bỏ qua nhất
Đây là attack vector số một trên headless WordPress mà nhiều người thiếu kinh nghiệm dễ bỏ qua nếu vibe-coding. Lý do dễ hiểu là bạn tin tưởng dữ liệu từ WordPress API vì “đó là CMS của mình mà, mình kiểm soát content.” Nhưng thực tế không đơn giản vậy.
WordPress cho phép HTML trong nội dung vì đó là by design, vì editor cần rich text. Khi nội dung đó đi qua API sang frontend headless và được render, bất kỳ script nào nằm trong content đều được thực thi. Ai có quyền viết bài trên WordPress? Bạn, người viết bài của bạn và nếu một trong những account đó bị xâm phạm, attacker có thể chèn script vào bài viết, script đó sẽ chạy trên trình duyệt của mọi người đọc bài.
Thậm chí không cần account bị hack. Nhiều site có chế độ kiểm soát lỏng lẻo, hoặc cho phép guest post qua form. Content từ những nguồn đó đi thẳng vào database WordPress → API trả ra → frontend render → XSS.
Với dự án AZDIGI (2000+ bài, nhiều người viết), mình không thể review từng bài một. Và thực tế, nhiều bài viết cũ từ thời WordPress classic editor chứa HTML rất “bẩn” vì paste từ Word với đủ loại inline styles, thậm chí có <script> tags vô tình bị để lại.
Mình hiểu sẽ có nhiều người nói mình tính hơi thừa vì hiện tại WordPress cũng đã có nhiều phương án chống XSS trong nội dung, form comments,…nhưng đối với mình, không bao giờ tin tưởng vào một nguồn duy nhất trong bảo mật, thậm chí cần phải Zero-trust7.
Giải pháp: sanitize MỌI nội dung từ API trước khi render, không có ngoại lệ.
Thachpham.com dùng DOMPurify, chạy được cả client-side và server-side, API đơn giản, whitelist tags và attributes mình cho phép. AZDIGI dùng sanitize-html, server-side only, 30M+ weekly downloads, battle-tested hơn 10 năm, xử lý được những edge cases mà regex không bao giờ catch được.
Và đây là điểm mình muốn nhấn mạnh: đừng tự viết sanitizer bằng regex. Ban đầu mình cũng viết, trông rất gọn gàng, nhỏ nhẹ:
function stripHtml(html) {
return html
.replace(/<script[^>]*>.*?<\/script>/gi, '')
.replace(/<[^>]+>/g, '')
.trim();
}Rồi mình phát hiện nó bị bypass bởi nested tags (<scr<script>ipt>alert(1)</script>), bị bypass bởi các sự kiện chèn tinh vi trong các tags được coi là hợp lệ (<img src=x onerror=alert(1)>), bị bypass bởi SVG injection, NULL bytes, Unicode lookalike characters,…đủ thứ hầm bà lằng xắng cấu. Mỗi lần fix một edge case lại lòi ra edge case khác. Cuối cùng mình vứt hết, chuyển sang thư viện chuyên dụng, viết một dòng code thay vì 50 dòng regex, mà an toàn hơn gấp bội.
Nguyên tắc: dùng whitelist approach (chỉ cho phép những gì mình biết là an toàn) thay vì blacklist approach (chặn những gì mình biết là nguy hiểm). Blacklist luôn có lỗ hổng vì bạn không thể liệt kê hết mọi vector tấn công. Whitelist thì chặt chẽ hơn, mọi thứ không nằm trong danh sách cho phép đều bị loại bỏ.
2. Elasticsearch injection – ít người nghĩ tới, nhưng nguy hiểm thật
Nếu bạn dùng Elasticsearch cho search (như cả hai dự án của mình), user input được truyền trực tiếp vào search query. Elasticsearch sử dụng Lucene query syntax với các ký tự đặc biệt: +, -, ", *, ?, (), {}, [], \, ~, ^. Mỗi ký tự đều có ý nghĩa riêng trong Lucene — * là wildcard, " là exact phrase, ~ là fuzzy search, () là grouping.
Nếu user input không được sanitize, hai kịch bản xảy ra:
- Case thường: query bị syntax error, Elasticsearch trả về lỗi, user thấy “Không tìm thấy kết quả” (UX tệ nhưng không nguy hiểm).
- Case củ chuối: attacker xào nấu một query đặc biệt để khiến Elasticsearch thực hiện wildcard search trên toàn bộ index (
*:*), dẫn tới queries cực kỳ nặng (*wordpress*trên 2000+ documents), hoặc regex queries tốn CPU, biến tính năng search đáng tự hào này thành công cụ DoS Elasticsearch server.
Giải pháp đơn giản mà hiệu quả: strip tất cả Lucene special characters khỏi user input trước khi truyền vào query, thay bằng space, trim lại. Chấp nhận đánh đổi là user không dùng được tính năng này, nhưng thực tế họ cũng chưa chắc là biết để dùng nên bỏ luôn là hợp lý.
function sanitizeSearchQuery(query) {
return query
.replace(/[+\-=&|><!(){}[\]^"~*?:\\/]/g, ' ')
.trim();
}Ngoài ra, mình còn thêm length limit cho search query (tối đa 200 ký tự — chẳng ai search query dài hơn thế trong thực tế) và rate limiting riêng cho search endpoint (nghiêm ngặt hơn các endpoint khác vì search queries tốn resource hơn).
3. “Hấp diêm” GraphQL
WPGraphQL cho phép request tối đa 100 bài mỗi lần. Mỗi bài viết trên AZDIGI có nội dung dài (hướng dẫn kỹ thuật, nhiều code blocks, nhiều ảnh inline), dễ dàng đạt 50-100KB mỗi bài. Một kết quả phản hồi từ GraphQL có thể lên tới 10MB.
Attacker không cần khai thác lỗ hổng nào cả, chỉ cần gửi liên tục gửi yêu cầu hợp lệ lấy 100 bài đầy đủ nội dung. Node.js phải parse JSON 10MB mỗi lần, mà số lượng này nhân lên vài chục nghìn requests thì ôi thôi con server nó lăn ra chết là cái chắc.
Giải pháp mình áp dụng: check Content-Length header trước khi gọi response.json(). Nếu response size vượt ngưỡng (mình set 10MB) → reject ngay, không parse.
const response = await fetch(GRAPHQL_URL, { ... });
const contentLength = response.headers.get('content-length');
if (contentLength && parseInt(contentLength) > 10 * 1024 * 1024) {
throw new Error('GraphQL response exceeds size limit');
}
const data = await response.json();10MB là số mình chọn dựa trên thực tế: 100 bài × 100KB/bài = 10MB. Đủ lớn để không ảnh hưởng nhu cầu sử dụng, đủ nhỏ để ngăn tràn bộ nhớ. Nếu site bạn có bài viết ngắn hơn, hạ ngưỡng xuống tương ứng.
Một lớp bảo vệ nữa: ở tầng BFF, mình không bao giờ request 100 bài cùng lúc cho frontend rendering. BFF luôn request đúng số bài cần thiết (12 bài/trang cho archive, 1 bài cho single post). Chỉ cache warming mới fetch nhiều bài, và warming chạy ở background với logic thử lại riêng, fail thì thử lại, không ảnh hưởng user-facing requests.
4. Security headers – phòng thủ nhiều lớp
WordPress truyền thống có plugin tự thêm security headers. Headless thì bạn tự set, và nhiều developer quên hoàn toàn phần này vì “frontend là Astro/Next.js, không có gì nguy hiểm.”
Sai. Mọi phản hồi qua HTTP – đặc biệt là các endpoint API đều cần security headers.
Lưu ý: API endpoint ở đây là các endpoint của chính frontend, không phải API của WordPress backend. Khi build headless, frontend của bạn thường cần tạo một số API route riêng để phục vụ các tính năng tương tác, ví dụ /api/search cho tìm kiếm, /api/contact cho form liên hệ, /api/comments cho bình luận. Những endpoint này nằm trên cùng domain với frontend (thachpham.com/api/…), do bạn tự viết, và trả về dữ liệu JSON trực tiếp cho trình duyệt. Đây chính là những endpoint cần được bảo vệ bằng security headers, vì chúng là phần “mở” duy nhất mà user (và attacker) có thể truy cập trực tiếp.
Lý do là nếu ai đó truy cập thẳng URL của API trên trình duyệt (gõ vào thanh địa chỉ, hoặc bị dẫn đến qua một liên kết độc hại từ bên ngoài), trình duyệt sẽ hiển thị nội dung phản hồi trực tiếp. Không có security headers, trình duyệt có thể bị lừa chạy mã độc nằm trong phản hồi JSON, hoặc cho phép nhúng API endpoint vào trang web khác dưới dạng iframe để đánh cắp thao tác người dùng (clickjacking), hoặc hiểu nhầm nội dung JSON thành HTML rồi thực thi nó.
Headers mình set cho mọi API endpoint trên cả hai dự án (gom tất cả vào middleware):
Content-Security-Policy: default-src 'none' — nghiêm ngặt nhất có thể cho API response. Không cho phép load bất kỳ resource nào (script, style, image, font). Nếu ai đó chèn mã độc hại vào JSON response, trình duyệt sẽ từ chối thực thi.
X-Content-Type-Options: nosniff – ngăn trình duyệt tự “đoán” định dạng nội dung. Bình thường khi server trả về JSON, trình duyệt biết đó là dữ liệu, không phải trang web. Nhưng nếu không có header này và nội dung JSON tình cờ chứa đoạn trông giống HTML, trình duyệt có thể hiểu nhầm rồi thực thi nó như một trang web, mở ra lỗ hổng chèn mã độc.
X-Frame-Options: DENY – ngăn trang web khác nhúng API endpoint vào bên trong trang của họ. Nếu không có header này, kẻ tấn công có thể giấu API endpoint vào một trang web giả, rồi dụ người dùng click vào. Kiểu tấn công này được gọi là clickjacking.
Như mình có nói ở trên, với bảo mật thì phải luôn áp dụng defense-in-depth (bảo mật đa lớp). Mỗi header riêng lẻ có vẻ “thừa”, ai lại gõ URL API vào trình duyệt? Nhưng bảo mật không phải làm cho “trường hợp bình thường” mà làm cho “trường hợp ai đó cố tình tấn công.”Tin mình đi, attacker rất sáng tạo trong các việc này.
Ngoài API endpoints, frontend pages cũng cần CSP riêng, nhưng phức tạp hơn vì phải allow scripts, styles, images, fonts mà site cần. Mình dùng webserver để khai báo CSP, strict nhất có thể nhưng vẫn cho phép resources cần thiết (Google Analytics, CDN assets, Elasticsearch endpoint). Việc này để tránh website thực thi các đoạn mã độc nếu bị lỡ chèn vào website (các mã redirect qua trang tiếng Nhật, quảng cáo bet,…) vì thường các file .js bị chèn trái phép này được load từ một domain bên ngoài để attacker có thể theo dõi và kiểm soát, update.
Riêng azdigi.com thì mình bỏ luôn CSP ngoài frontend vì đang sử dụng Subiz cho tính năng chat, mà anh này luôn liên tục đổi domain theo dạng random (subiz123abc.com và rất nhiều) cho các script 😪, trang azdigi.com mất cái chat một buổi là coi như mất doanh thu 🥲. Ai làm ở Subiz thì ping đoạn này tới cấp trên để xem xét nhé.
5. Rate limiting – tự build nhưng phải đúng cách
WordPress có plugin rate limiting (Wordfence limit login attempts, WP Rate Limit, v.v.). Headless thì tự implement, và đây là nơi nhiều chi tiết nhỏ quyết định hệ thống có thực sự bảo vệ được hay không.
Mình rate limit tất cả các endpoint chịu tải nặng hoặc có khả năng bị lạm dụng: search queries (Elasticsearch tốn resource, dễ bị spam), form submissions (contact form, report form — chặn spam bot), API endpoints phía public (archive pages, single post), các endpoint sử dụng AI (ví dụ tính năng tư vấn gói dịch vụ của azdigi.com).
Thuật toán mình dùng là sliding window thay vì fixed window. Fixed window có một vấn đề: nếu limit là 100 requests/phút, user gửi 100 requests ở giây 59 rồi 100 requests ở giây 61 → 200 requests trong 2 giây mà không bị chặn vì rơi vào hai windows khác nhau. Sliding window đếm chính xác số requests trong 60 giây gần nhất, không có khe hở.
Chi tiết quan trọng khi deploy dự án qua proxy (Cloudflare): request đến Node.js có IP là IP của proxy, không phải IP của user. Nếu rate limit theo IP mà dùng IP của proxy → toàn bộ users bị rate limit chung → user thật bị chặn oan.
Mình xử lý bằng hàm đọc IP theo thứ tự ưu tiên, tuỳ vào hạ tầng phía trước là gì:
/**
* Lấy IP thật của người dùng, hỗ trợ nhiều loại proxy
* Ưu tiên: CF-Connecting-IP > X-Forwarded-For > X-Real-IP > fallback
*/
export function getClientIP(request: Request): string {
// Cloudflare tự gán header này — một IP duy nhất, không bị giả mạo
const cfIP = request.headers.get('cf-connecting-ip');
if (cfIP) {
return cfIP.trim();
}
// Proxy thông thường — lấy IP đầu tiên trong chuỗi (IP gốc của client)
const forwarded = request.headers.get('x-forwarded-for');
if (forwarded) {
return forwarded.split(',')[0].trim();
}
// Nginx thường dùng header riêng
const realIP = request.headers.get('x-real-ip');
if (realIP) {
return realIP.trim();
}
return '127.0.0.1';
}Logic ưu tiên từ trên xuống: nếu đứng sau Cloudflare thì CF-Connecting-IP luôn có mặt và đáng tin nhất, một giá trị duy nhất do Cloudflare tự set, client không can thiệp được. Nếu không qua Cloudflare mà qua proxy khác (AWS ALB, Vercel, v.v.) thì đọc X-Forwarded-For, header này là danh sách IP ngăn cách bằng dấu phẩy, IP đầu tiên là IP gốc của người dùng. Nếu đứng sau Nginx cấu hình proxy_set_header X-Real-IP, dùng header đó. Fallback cuối cùng là 127.0.0.1 cho môi trường dev local không qua proxy nào.
Tuy nhiên vẫn cần cẩn thận: nếu attacker gửi request thẳng đến server Node.js mà bypass Cloudflare, họ có thể tự đặt header CF-Connecting-IP giả. Giải pháp là chỉ cho phép server nhận request từ dải IP của Cloudflare (Cloudflare công khai danh sách IP của họ), request từ IP khác bị chặn ngay, không cần kiểm tra gì thêm. Làm đúng bước này thì CF-Connecting-IP luôn đáng tin.
Mình cũng áp dụng bộ nhớ dự phòng cho rate limiting: khi Redis down, chuyển sang in-memory counter. Khả năng lưu trữ nhỏ hơn (không share cross-process) nhưng vẫn rate limit được ở mức cơ bản. Không có fallback, Redis down → rate limiting mất → site mở cửa cho hành động lạm dụng.
6. Webhook security – xác thực request từ WordPress
Webhook endpoint /api/webhook/wordpress nhận POST request từ WordPress khi có bài mới, bài sửa, hoặc bài xóa → thực hiện xoá cache Redis. Nhưng endpoint này phải công khai (thực ra là có thể công khai nhưng an toàn nếu cho backend và frontend chạy cùng tailnet của Tailscale), bất kỳ ai biết URL đều có thể gửi fake webhook request → trick hệ thống xóa cache → gây cache miss liên tục → tăng load WordPress.
Giải pháp: webhook secret. WordPress gửi request kèm header chứa chữ ký HMAC (hash của request body + secret key). Frontend chứng thực trước khi xử lý, nếu signature không khớp, reject request.
function verifyWebhookSignature(body: string, signature: string, secret: string): boolean {
const expected = crypto
.createHmac('sha256', secret)
.update(body)
.digest('hex');
return crypto.timingsSafeEqual(
Buffer.from(signature),
Buffer.from(expected)
);
}Chi tiết nhỏ nhưng quan trọng: dùng timingSafeEqual thay vì === để so sánh signature. So sánh string bình thường có thể bị timing attack, attacker đo thời gian phản hồi để đoán từng ký tự của signature. timingSafeEqual so sánh trong constant time, không leak thông tin qua timing.
Ngoài ra, mình thêm IP whitelist cho webhook endpoint tại frontend, chỉ chấp nhận requests từ IP của WordPress headless (check theo IP private của Tailscale). Attacker có biết webhook URL và brute force secret cũng không gửi được request từ IP khác.
7. WordPress backend – ẩn nhưng không được quên
Headless làm giảm rủi ro bị tấn công cho frontend, nhưng WordPress backend vẫn tồn tại và vẫn cần bảo vệ. Thực tế, vì backend giờ chỉ serve API (không có frontend traffic), nhiều người lơ là bảo mật cho nó.
Sai. WPGraphQL endpoint vẫn public (cần public để frontend fetch data). WordPress admin vẫn accessible (bạn cần vào viết bài). REST API vẫn hoạt động (dù bạn dùng GraphQL, REST API vẫn bật mặc định). Tất cả đều là attack vectors.
Những gì mình setup cho WordPress backend ở cả hai dự án:
Một, cũng là quan trọng nhất đó là WordPress backend chỉ có thể truy cập được từ mạng nội bộ (sử dụng Tailscale để tạo mạng nội bộ cho các VPS kể cả khác mạng, khác quốc gia), mỗi lần mình muốn vào backend viết bài thì sẽ kết nối voà Tailscale trên máy tính. Bù lại nếu dùng phương án này, một số plugin cần kết nối vào backend sẽ bị chặn hoàn toàn, ví dụ như plugin WPML, Wordfence (để scan mã độc),…
Hai, tách domain hoàn toàn: WordPress backend ở subdomain riêng (hoặc thậm chí internal domain không resolve public giống như Tailscale có hỗ trợ). Frontend ở domain chính. Không có liên kết trực tiếp nào từ frontend đến WordPress admin. User không biết WordPress tồn tại ở đâu.
Ba, auto-update: vì WordPress backend giờ đơn giản hơn (không cần lo theme conflict, plugin conflict phía frontend), auto-update cho core, plugins, và PHP version trở nên an toàn hơn. Mình bật auto-update toàn bộ từ core đến các plugin bắt buộc dùng (Rank Math SEO, WPGraphQL,..)
Lưu ý thêm: Ngoài bảo mật ở tầng ứng dụng, thì server chạy backend cũng cần phải bảo mật tốt với các phương án như không chạy chung với các ứng dụng khác, chỉ cho phép SSH qua Tailscale, không cho đăng nhập SSH bằng mật khẩu,…
Tổng kết: bảo mật headless khó hơn nhưng tốt hơn
WordPress truyền thống cho bạn cài plugin, bật vài settings, xong. Nhanh, tiện, nhưng bạn phụ thuộc hoàn toàn vào nhà phát triển. Plugin có lỗ hổng? Bạn chờ họ vá. Plugin ngừng bảo trì? Bạn tìm plugin khác. Plugin xung đột với nhau? Bạn tự đi debug.
Headless cho bạn toàn quyền kiểm soát, nhưng trách nhiệm cũng hoàn toàn. Mọi lớp bảo vệ đều do bạn thiết kế, triển khai, và bảo trì. Không có plugin nào làm thay.
Nghe nặng nề, nhưng kết quả là hệ thống security mà bạn hiểu từng dòng code. Bạn biết chính xác CSP policy cho phép gì và chặn gì. Bạn biết rate limit bao nhiêu requests/phút cho mỗi endpoint. Bạn biết webhook secret nằm ở đâu và verify bằng thuật toán gì.
Và quan trọng nhất: rủi ro bị tấn công thực sự nhỏ hơn đáng kể. WordPress truyền thống expose hàng trăm endpoints, hàng ngàn hooks, hàng chục plugin, mỗi thứ là một rủi ro tiềm ẩn. Headless frontend expose vài API endpoints mà bạn tự viết, tự validate, tự rate limit. Backend WordPress ẩn sau private network. Attacker thậm chí còn không thấy được trang login của bạn.
Mình không nói headless an toàn hơn WordPress truyền thống trong mọi trường hợp, nếu bạn không lường trước các rủi ro, headless có thể kém an toàn hơn vì thiếu lớp bảo vệ mặc định của các plugin bảo mật. Nhưng nếu bạn đầu tư thời gian triển khai các biện pháp trên (và thành thật mà nói, phần lớn chỉ là vài chục dòng code mỗi thứ), kết quả là hệ thống bảo mật chặt chẽ hơn, và ít phụ thuộc bên thứ ba hơn.
13. Hình ảnh bài viết – bài toán không ai nói trước khi bạn chuyển sang headless
WordPress truyền thống xử lý hình ảnh cực kỳ đơn giản: upload ảnh lên Media Library → WordPress tự tạo các kích thước thumbnail → chèn vào bài viết → xong. Ảnh nằm trong /wp-content/uploads/, tải trực tiếp từ cùng domain, mọi thứ hoạt động mượt mà. Bạn muốn tối ưu thêm thì cài ShortPixel hoặc Imagify, plugin tự nén ảnh, tự chuyển sang WebP, tự serve qua CDN. Không cần hiểu gì về responsive images, không cần biết <picture> tag là gì.
Chuyển sang headless, bạn gặp ngay một vấn đề rất cơ bản mà gần như không tutorial nào đề cập: ảnh trong bài viết không load được.
Tại sao ảnh không load được?
WordPress backend của bạn giờ nằm ở một domain riêng (ví dụ blog.thachpham.com) và domain này bị chặn truy cập từ bên ngoài — chỉ cho phép server Astro gọi API, không cho phép trình duyệt người dùng truy cập trực tiếp. Đây là thiết kế bảo mật đúng đắn: WordPress backend không nên lộ ra public.
Nhưng khi WordPress trả content bài viết qua GraphQL, mọi thẻ <img> trong bài đều trỏ về domain WordPress gốc:
<img src="https://thachpham.com/wp-content/uploads/2026/02/image.jpg" alt="...">
Trình duyệt người dùng cố load ảnh từ blog.thachpham.com → bị chặn → ảnh vỡ. Toàn bộ ảnh trong bài viết, ảnh đại diện, ảnh trong gallery – tất cả đều biến mất.
Với WordPress truyền thống bạn không gặp vấn đề này vì frontend và backend cùng domain, ảnh upload lên đâu thì tải từ đó.
Giải pháp: offload ảnh lên Cloudflare R2 + phân phối qua Workers
Mình giải quyết bằng kiến trúc ba tầng: lưu trữ trên Cloudflare R2, phân phối qua Cloudflare Workers, và tối ưu bằng Cloudflare Image Transformations.
Cloudflare R2 đóng vai trò storage — thay thế thư mục /wp-content/uploads/ của WordPress. Khi upload ảnh lên WordPress, ảnh được đẩy song song lên R2. R2 có ưu điểm lớn so với lưu trực tiếp trên server WordPress: không tốn phí egress (R2 miễn phí bandwidth ra ngoài, khác S3 của AWS), nằm sẵn trong hệ sinh thái Cloudflare nên tích hợp với Workers và CDN cực nhanh, và không phụ thuộc vào server WordPress, server WordPress có chết thì ảnh vẫn serve bình thường.
Cloudflare Workers đứng trước R2, đóng vai trò proxy thông minh. Thay vì để trình duyệt gọi thẳng R2 (URL xấu, không kiểm soát được), Workers nhận request từ domain cdn.thachpham.com, xử lý URL, rồi lấy ảnh từ R2 trả về. Workers cũng là nơi mình gắn thêm logic tối ưu: kiểm tra cache, thêm headers, và quan trọng nhất là gọi Cloudflare Image Transformations.
Cloudflare Image Transformations là phần thay đổi cuộc chơi. Thay vì phải tạo sẵn nhiều kích thước ảnh lúc upload (như WordPress vẫn làm với thumbnail, medium, large, full), mình chỉ cần lưu ảnh gốc một bản duy nhất trên R2. Khi cần kích thước nào, trình duyệt request kèm tham số, Workers chuyển tham số đó cho Image Transformations, ảnh được resize, nén, chuyển định dạng ngay lúc request, tại edge server gần người dùng nhất.
URL chuyển đổi rất trực quan:
Ảnh gốc trên WordPress:
https://blog.thachpham.com/wp-content/uploads/2024/01/image.jpg
Qua CDN với tối ưu:
https://cdn.thachpham.com/2024/01/image.jpg?w=800&q=80&f=webp
Ba tham số cơ bản: w (chiều rộng pixel), q (chất lượng nén 0-100), f (định dạng: avif, webp, hoặc giữ nguyên). Chỉ cần thay tham số trong URL là có ảnh ở bất kỳ kích thước và định dạng nào, không cần tạo trước, không cần lưu nhiều bản.
Thông tin thêm: Mình có làm một plugin WordPress tên là CF R2 Storage & CDN để tích hợp giải pháp này vào các website WordPress nhanh chóng, đang chờ WordPress.org duyệt và mình sẽ có bài viết sau.
Tích hợp vào Astro — biến mọi ảnh thành responsive tự động
Có CDN rồi, nhưng nếu mỗi lần chèn ảnh vào component phải tự viết thẻ <picture> với đầy đủ srcset cho AVIF, WebP, fallback — thì quá cực. Mình xây dựng một hệ thống gồm hai phần: bộ chuyển đổi URL và component tối ưu ảnh.
Bộ chuyển đổi URL nhận URL ảnh gốc từ WordPress, đổi domain từ blog.thachpham.com sang cdn.thachpham.com, bỏ phần /wp-content/uploads/ thừa, thêm tham số tối ưu vào. Một hàm duy nhất, gọi ở bất kỳ đâu cần hiển thị ảnh.
Component tối ưu ảnh (OptimizedImage) nhận URL ảnh và preset, tự động sinh ra thẻ <picture> hoàn chỉnh với ba lớp:

<picture>
<!-- Lớp 1: AVIF — nén tốt nhất, trình duyệt mới hỗ trợ -->
<source type="image/avif"
srcset="...?w=400&f=avif 400w, ...?w=800&f=avif 800w"
sizes="(min-width: 1024px) 33vw, 100vw" />
<!-- Lớp 2: WebP — nén tốt, hầu hết trình duyệt hỗ trợ -->
<source type="image/webp"
srcset="...?w=400&f=webp 400w, ...?w=800&f=webp 800w"
sizes="(min-width: 1024px) 33vw, 100vw" />
<!-- Lớp 3: Ảnh gốc — fallback cho trình duyệt cũ -->
<img src="...?w=800&q=80"
srcset="...?w=400 400w, ...?w=800 800w"
sizes="(min-width: 1024px) 33vw, 100vw"
loading="lazy" decoding="async" />
</picture>
Trình duyệt tự chọn lớp phù hợp nhất: Chrome mới nhất lấy AVIF (nén nhỏ nhất), Safari lấy WebP, trình duyệt cũ lấy ảnh gốc. Trong mỗi lớp, trình duyệt lại chọn kích thước phù hợp với viewport — điện thoại lấy ảnh 400px, desktop lấy 800px. Tất cả tự động, người viết bài không cần quan tâm.
Preset system — không phải ảnh nào cũng cần xử lý giống nhau
Mình định nghĩa sẵn bốn preset cho bốn ngữ cảnh khác nhau:
Ảnh thumbnail trên lưới bài viết (grid) cần nhỏ gọn: chỉ tạo hai kích thước 400px và 800px. Trên desktop hiển thị dạng 3 cột nên mỗi ảnh chỉ chiếm 33% chiều rộng màn hình, trên điện thoại chiếm 100%.
Ảnh đại diện bài viết (hero) cần lớn và sắc nét: tạo ba kích thước 800, 1200, 1600px. Chiếm toàn bộ chiều rộng trang nhưng giới hạn tối đa 1600px — không cần ảnh 4K cho web.
Ảnh trong nội dung bài viết (content) cần vừa phải: ba kích thước 600, 900, 1200px. Vùng nội dung bài viết giới hạn ở 900px nên không cần ảnh rộng hơn, trừ khi người đọc mở lightbox xem ảnh lớn.
Ảnh card trong chuỗi bài viết (series) cần nhỏ: hai kích thước 400 và 600px. Hiển thị dạng 2 cột trên tablet, 1 cột trên điện thoại.
Khi dùng trong component, chỉ cần truyền preset là xong:
<!-- Ảnh lưới bài viết — tự động dùng kích thước nhỏ -->
<OptimizedImage src={post.featuredImage} preset="grid" loading="lazy" />
<!-- Ảnh hero — tự động dùng kích thước lớn, load ngay không chờ -->
<OptimizedImage src={heroImage} preset="hero" loading="eager" fetchpriority="high" />
Người viết bài trên WordPress không cần biết gì về responsive images. Họ upload ảnh gốc, viết bài bình thường. Hệ thống tự động: WordPress lưu ảnh → đẩy lên R2 → Astro nhận content qua GraphQL → phát hiện thẻ <img> → chuyển URL sang CDN → sinh thẻ <picture> với đầy đủ AVIF/WebP/fallback và srcset phù hợp. Từ một ảnh gốc duy nhất, tạo ra hàng chục phiên bản tối ưu cho mọi thiết bị và trình duyệt.
Xử lý ảnh trong nội dung bài viết — phần khó nhất
Component OptimizedImage xử lý tốt cho ảnh đại diện, ảnh lưới – những ảnh mình kiểm soát được trong code. Nhưng ảnh chèn trong nội dung bài viết thì khác: chúng nằm trong HTML content trả về từ GraphQL, là các thẻ <img> thô từ WordPress editor.
Mình viết thêm hàm transformContentImages để xử lý tự động. Hàm này quét toàn bộ HTML content, tìm mọi thẻ <img>, và biến đổi từng thẻ, hoặc thêm cơ chế chỉ quét thẻ <img> trong một số class nhất định.
Trước (từ WordPress):
<img src="https://thachpham.com/wp-content/uploads/2024/image.jpg" alt="Minh hoạ">
Sau (đã tối ưu):
<a href="...?w=1920&q=90" class="lightbox-trigger">
<picture>
<source type="image/avif" srcset="...?w=600&f=avif 600w, ...?w=900&f=avif 900w" ...>
<source type="image/webp" srcset="...?w=600&f=webp 600w, ...?w=900&f=webp 900w" ...>
<img src="...?w=900" srcset="...?w=600 600w, ...?w=900 900w" loading="lazy" ...>
</picture>
</a>
Mỗi ảnh trong bài viết được bọc trong link lightbox (click vào xem ảnh gốc lớn 1920px, chất lượng 90%), bên trong là thẻ <picture> đầy đủ ba lớp định dạng với preset content. Toàn bộ quá trình xảy ra tự động lúc render, người viết bài không cần làm gì khác ngoài chèn ảnh như bình thường trên WordPress.
Tuy nhiên nếu bạn cần tiết kiệm chi phí CloudFlare Transformation thì có thể không cần tính năng xử lý ảnh responsive mà chỉ cần xử lý ảnh AVIF/WEBP là được.
Kết quả thực tế
Bandwidth giảm 40-70% so với phục vụ ảnh gốc, AVIF nén tốt hơn JPEG rất nhiều, đặc biệt với ảnh chụp màn hình (dạng nội dung phổ biến trên blog kỹ thuật). Điểm LCP (Largest Contentful Paint) cải thiện rõ rệt vì trình duyệt load đúng kích thước ảnh cần thiết thay vì ảnh gốc 3000px rồi thu nhỏ lại. Và R2 miễn phí bandwidth nên chi phí gần như bằng không, chỉ trả tiền storage (rất rẻ) và Image Transformations (tính theo số lượt transform, có free tier khá thoải mái).
Website nào thật sự cần headless?
Không phải website nào cũng cần headless và mình nói thật, nếu bạn chỉ cần một blog cá nhân đơn giản hay một trang giới thiệu doanh nghiệp vài trang thì WordPress truyền thống vẫn hoàn toàn ổn và phù hợp với WordPress truyền thống.
Việc blog mình chuyển qua headless là để mình thoả mãn sự tự do trong việc thiết kế giao diện và các tính năng, việc này tăng đáng kể thời gian mình phải bảo trì cho blog.
Nhưng có những loại website mà headless không chỉ là tốt hơn, mà là vượt trội hoàn toàn so với kiến trúc monolithic truyền thống.
Website tin tức và tạp chí online (Media & Publishing)
Đây là lĩnh vực mà headless WordPress thể hiện rõ nhất sức mạnh. Qz.com (Quartz) – trang tin tức kinh tế nổi tiếng, là một trong những website đầu tiên trên thế giới chạy production với WPGraphQL8, thậm chí trước cả khi người tạo ra WPGraphQL dùng nó cho chính mình.
Lý do rất đơn giản là các trang tin tức cần tốc độ. Khi một bài được viral hoặc tin nóng hổi, có rất nhiều người truy cập cùng lúc. WordPress truyền thống phải query database, chạy qua PHP, load tất cả plugin, render HTML cho mỗi request và khi traffic tăng đột biến, server sập là chuyện thường. Với headless, frontend có thể tối ưu thành các tập tin HTML tĩnh hoặc được render sẵn (SSG/ISR), phục vụ qua CDN toàn cầu (Edge Caching). Server WordPress chỉ làm một việc: cung cấp dữ liệu qua API khi cần rebuild, không phải xử lý hàng triệu request trực tiếp.
Ngoài ra, các toà soạn thường cần xuất bản nội dung ra nhiều kênh cùng lúc: website, app mobile, newsletter, Apple News, Google News, AMP. Với WordPress truyền thống, mỗi kênh là một hệ thống riêng. Với headless, một nguồn nội dung duy nhất phục vụ tất cả biên tập viên publish một lần, nội dung xuất hiện ở mọi nơi bằng cách phân phối qua REST API/GraphQL.
Website thương mại điện tử (E-commerce)
Nếu bạn đang chạy WooCommerce và cảm thấy trang sản phẩm load chậm, checkout laggy, Core Web Vitals lúc nào cũng đỏ thì headless chính là lời giải. Đây là chìa khoá mà bạn có thể biến một trang bán hàng thông thường phụ thuộc vào cấu trúc template của WordPress & WooCommerce, thành một trang bán hàng độc đáo, tính năng thiết kế dành riêng cho bạn, hoành tráng và hiệu năng cao.
Một case study điển hình mình tìm kiếm được là Gourmet Basket – cửa hàng quà tặng thực phẩm cao cấp tại Úc sau 8 năm chạy WooCommerce truyền thống, website ngày càng chậm do tích lũy quá nhiều plugin và logic phức tạp, đặc biệt trong các đợt sale cao điểm. Cuối năm 2022, họ chuyển sang kiến trúc headless WooCommerce với Next.js làm frontend9. Kết quả: giá trị đơn hàng trung bình (AOV) tăng 30%, thu hồi toàn bộ chi phí đầu tư trong 60 ngày. Tốc độ load trang giảm xuống còn 0.22 giây, chỉ số LCP chỉ 596ms, nhanh hơn cả Apple và Walmart. Lý do đơn giản là khi frontend được build bằng framework hiện đại (React, Next.js, Astro), trang sản phẩm load gần như tức thì, không còn phải chờ WooCommerce render PHP với hàng chục hook từ các plugin thanh toán, plugin đánh giá, plugin cross-sell, plugin tracking…
Headless e-commerce còn mở ra khả năng mà WooCommerce truyền thống không làm được: bạn có thể dùng WordPress + WooCommerce làm backend quản lý sản phẩm và đơn hàng, nhưng frontend là một Progressive Web App (PWA) chạy mượt như app native trên điện thoại. Hoặc cùng một catalog sản phẩm, bạn vừa hiển thị trên website, vừa đẩy ra app mobile, vừa tích hợp vào các sàn, Google Merchant,…tất cả từ một nguồn dữ liệu duy nhất.
Website doanh nghiệp đa nền tảng (Enterprise & Omnichannel)
Bạn có một tập đoàn với website chính, microsite cho từng chiến dịch marketing, app mobile cho khách hàng, portal nội bộ cho nhân viên, và chatbot hỗ trợ tự động. Nếu mỗi nền tảng dùng một CMS riêng, bạn sẽ có nội dung bị phân mảnh, không nhất quán, và tốn gấp nhiều lần chi phí vận hành.
Headless WordPress giải quyết điều này triệt để. Đội content chỉ cần quản lý nội dung ở một nơi — WordPress admin quen thuộc mà ai cũng biết dùng. Từ đó, API phân phối nội dung đến mọi kênh: website render bằng Next.js, app mobile dùng React Native,…
Theo báo cáo State of Headless của WP Engine năm 202410, 73% doanh nghiệp đã áp dụng kiến trúc headless cho website của họ. Và thị trường headless CMS đang tăng trưởng với tốc độ CAGR khoảng 22%11. Con số này cho thấy đây không phải xu hướng thử nghiệm, mà là hướng đi chính của doanh nghiệp hiện nay.
Website có lượng truy cập cao và cần hiệu năng tối đa
WordPress truyền thống có một giới hạn cố hữu: mỗi page view = một lần PHP execution + database query. Dù bạn có đặt thêm bao nhiêu lớp cache (page cache, object cache, OPcache, CDN), bản chất vẫn là server-side rendering trên PHP.
Với headless, bạn có thể áp dụng Static Site Generation (SSG) — toàn bộ trang được build sẵn thành HTML tĩnh tại thời điểm deploy. Kết quả? TTFB (Time to First Byte) gần như bằng 0 vì CDN chỉ cần trả về file có sẵn, không cần query gì. Như case study của chính thachpham.com, mặc dù mình dùng SSR nhưng TTFB giảm từ 700ms xuống 80ms, FCP từ 3 giây xuống 0,8 giây, điểm Pagespeed từ 60-70 lên 95+. Dĩ nhiên con số điểm có thể tối ưu hơn được nữa nhưng mình chưa có thời gian tập trung vào phần này.
Điều này đặc biệt quan trọng với SEO. Google đã chính thức dùng Core Web Vitals làm tín hiệu xếp hạng. Dữ liệu từ HTTP Archive mình đề cập ở đầu bài cũng nói lên được điều này, đó là sử dụng WordPress như headless CMS kết hợp với Astro sẽ cho khả năng tối ưu chỉ số Core Web Vitals tốt hơn.
Website cần cập nhật frontend thường xuyên mà không muốn ảnh hưởng backend
Đây là điểm yếu của WordPress thông thường mà nhiều agency và đội dev gặp phải. Với WordPress truyền thống, mỗi lần redesign là một dự án lớn: thay theme mới, kiểm tra từng plugin có tương thích không, migrate shortcode (nếu có dùng, và rất khổ), test lại toàn bộ chức năng. Hoặc là phải luôn duy trì một website trên môi trường staging để test, điều này rất phức tạp với các website có nhiều dữ liệu.
Với headless, frontend và backend là hai hệ thống hoàn toàn độc lập. Bạn muốn redesign? Cứ build frontend mới, trỏ vào cùng API endpoint, test xong thì chuyển DNS. WordPress backend không hề biết và không hề bị ảnh hưởng, đội content vẫn đang viết bài bình thường trong admin.
Thậm chí nếu WordPress bị sập do update plugin lỗi hay server gặp sự cố, frontend vẫn hoạt động bình thường vì nếu sử dụng SSG, hoặc sử dụng SSR nhưng caching dài hạn trên edge CDN. Đây là mức độ an toàn mà WordPress truyền thống không bao giờ đạt được.
Vậy website nào KHÔNG cần headless?
Nếu bạn đang chạy một blog cá nhân, landing page đơn giản, hoặc website doanh nghiệp nhỏ mà không có nhu cầu đặc biệt về hiệu năng hay đa nền tảng, WordPress truyền thống với một theme nhẹ vẫn là lựa chọn hợp lý. Chi phí vận hành thấp hơn, không cần developer chuyên frontend, và hệ sinh thái plugin phong phú giúp bạn làm được hầu hết mọi thứ.
Headless phù hợp nhất khi bạn có ít nhất một trong những nhu cầu sau:
- Hiệu năng là ưu tiên hàng đầu (e-commerce, media, high-traffic)
- Nội dung cần phục vụ nhiều kênh (web, app, IoT, voice)
- Đội dev muốn dùng framework hiện đại (React, Astro, Svelte, Vue)
- Cần tách biệt frontend và backend cho bảo mật hoặc workflow
- Muốn tận dụng AI/vibe coding để phát triển và thực thi nhanh
Nếu bạn thấy mình đang gật đầu với 2-3 điều trên, thì headless không phải là kiểu có thì tốt, mà là bước tiến cần thiết.
Quy trình thực tế: từ WordPress truyền thống sang headless bằng vibe coding
Nhiều bài viết về headless WordPress mô tả quy trình rất “sách giáo khoa”: phân tích yêu cầu → thiết kế kiến trúc → chọn tech stack → code từ đầu → tích hợp API → deploy. Nghe thì đúng nhưng thực tế mình không làm vậy.
Thực tế hiện nay ai cũng dùng AI để code hết rồi nên mình sẽ trình bày phần này theo kiểu vibe coding – giống như cách mình đã làm và không dẫn chứng code dài dòng vì cái đó cho việc của AI.
Xin nhắc lại thêm rằng, vibe coding không có nghĩa là bạn tắt máy đi ngủ cho AI nó làm. Hãy luôn review code, và phải hiểu nó đang làm gì vì hiện tại AI luôn có xu hướng rất dễ mắc lỗi nhưng lại “ngáo quyền lực” tự cho là mình đúng. Nếu nó có code bạn không hiểu, hãy bắt nó giải thích.
Dưới đây là quy trình thực tế mình đã dùng để chuyển thachpham.com sang headless, từng bước một.
Bước 1: Thiết kế giao diện trước – đừng code khi chưa biết mình muốn gì
Theo một quy trình để phát triển website mà có API hiện nay, thường là sẽ được bắt đầu từ API trước tiên (API-first approach). Nhưng với WordPress headless, phần này đã có WPGraphQL lo nên theo quan điểm cá nhân của mình là làm design frontend trước tiên để thấy trước được mình cần gì, tránh sửa đi sửa lại thiết kế khi đã tích hợp WordPress headless sẽ làm mất thời gian.
Công cụ mình dùng là Readdy.AI hoặc AI Studio của Google, cả hai đều có live preview, mô tả bằng lời giao diện bạn muốn là AI sinh ra ngay, chỉnh sửa trực tiếp trên preview cho đến khi ưng ý. Mình làm solo cho chính bản thân mình nên không cần phải vẽ trước design trên Figma gì cả, giờ có AI rồi thì cứ chơi thẳng design trực tiếp cho tiện.

Ở bước này chỉ cần thiết kế trang chủ thật kỹ kèm theo một branding guide rõ ràng: bảng màu, font chữ, khoảng cách, bo góc, phong cách nút bấm, cách trình bày card bài viết. Trang chủ là nơi thể hiện toàn bộ ngôn ngữ thiết kế của website, có trang chủ chắc chắn rồi thì các trang con (bài viết, lưu trữ, tìm kiếm) chỉ cần tuân theo cùng ngôn ngữ đó, Claude Code có thể phát triển tiếp mà không lệch phong cách.
Bước 2: Tải source code về và khởi tạo dự án
Readdy.AI và AI Studio xuất source code dạng React. Tải về, đây sẽ là bản tham chiếu thiết kế cho toàn bộ dự án không phải code production, mà là “bản vẽ” để AI hiểu bạn muốn giao diện trông như thế nào. Hãy tải và copy nó vào thư mục dự án, đặt tên theo kiểu “original_design” để AI nó dễ hiểu. Lưu ý là sau này khi chuyển thiết kế qua Astro/Next.js thì hãy xoá đi để tránh nó chèn code sai chỗ.
Tạo một dự án mới với Claude Code và cài đặt Superpower — bộ skills và agent giúp Claude Code làm việc có hệ thống hơn. Thay vì chat tự do kiểu “làm cho tôi cái này”, Superpower cung cấp các lệnh có cấu trúc để brainstorm, lên kế hoạch, và thực thi từng bước — phù hợp cho dự án phức tạp như chuyển đổi headless.
Gợi ý: Nếu bạn cần bộ agent và skills thông minh hơn, hãy trải nghiệm ClaudeKit và bạn sẽ không hối hận. Nó cũng giống Superpower nhưng ở cấp độ tinh vi hơn.
Bước 3: Brainstorm chọn tech stack
Chạy /superpowers:brainstorm để thảo luận với AI về tech stack phù hợp. Đưa vào context: dự án là blog cá nhân hay blog công ty, bao nhiêu bài viết, cần hỗ trợ đa ngôn ngữ không, traffic dự kiến bao nhiêu, team bao nhiêu người maintain, bạn quen framework nào.
Ở bước này mình đã chọn Astro + Svelte cho thachpham.com (Astro cho routing và SSR, Svelte cho các interactive component vì cú pháp đơn giản hơn React rất nhiều khi vibe coding). Nhưng lựa chọn của bạn có thể khác, Next.js + React nếu team quen React, Nuxt + Vue nếu thích Vue. Quan trọng là AI hiểu rõ mục tiêu để đưa ra gợi ý phù hợp, không phải chọn kiểu “framework hot nhất.”
Bước 4: Lên kế hoạch convert giao diện
Chạy /superpowers:write-plan với mục tiêu: convert source React tải từ Readdy/AI Studio sang framework đã chọn (chỉ rõ tên thư mục). Kế hoạch cần bao gồm: cấu trúc thư mục, tách component nào ra riêng, mapping từ React component sang Svelte/Vue component, xử lý CSS (chuyển sang Tailwind hoặc giữ CSS module). Prompt ví dụ của mình:
Prompt:
/superpowers:write-plan Hãy thực hiện chuyển đổi thiết kế frontend gốc tại thư mục original_design/ vào dự án chính tại thư mục src/, tách các thành phần trên website thành dạng component để tái sử dụng với Svelte và cấu trúc tương thích với Astro trong dự án.Claude Code sẽ thực hiện convert theo kế hoạch. Kết quả: bạn có frontend hoàn chỉnh chạy được trên framework mới, giao diện giống hệt bản thiết kế, nhưng chưa có dữ liệu thật.
Bước 5: Hoàn thiện thiết kế với mock data
Tiếp tục /superpowers:write-plan để thiết kế các trang còn lại: trang nội dung bài viết, trang lưu trữ (archive), trang chuyên mục, trang tìm kiếm, trang 404. Yêu cầu AI tạo mock data giả vào như tiêu đề bài viết, đoạn mô tả, ảnh placeholder,…để thấy giao diện trông như thế nào với nội dung thật.
Bước này rất quan trọng và đừng bỏ qua. Nhiều vấn đề chỉ lộ ra khi có data: tiêu đề quá dài bị tràn, ảnh tỷ lệ không đều bị méo layout, bài viết không có ảnh đại diện thì card trông ra sao, phân trang khi có 100+ trang hiển thị thế nào. Fix hết ở bước này với mock data, đỡ hơn nhiều so với fix sau khi đã tích hợp API thật.
Bước 6: Chuẩn bị WordPress backend
Song song với việc hoàn thiện frontend, chuẩn bị WordPress backend. Sao chép website WordPress hiện có sang một môi trường staging (hoặc cài WordPress mới nếu build từ đầu). Cài đặt và kích hoạt các plugin cần thiết.
Tips: Nếu bạn muốn cho backend sạch sẽ nhất nhưng vẫn lại giữ liệu gốc, thì có thể cài website mới, thực hiện export nội dung qua công cụ Tools => Export và nhập vào lại website mới. Nếu website nhiều hình ảnh thì copy lại thư mục wp-content/uploads để dùng lại, và export dữ liệu Media từ website cũ qua website mới.
WPGraphQL – bắt buộc, đây là cầu nối dữ liệu chính. WPGraphQL cho phép query bài viết, chuyên mục, tag, media, menu, và hầu hết mọi loại dữ liệu WordPress qua GraphQL.
Nếu dùng SEO plugin (Yoast, Rank Math) thì cài thêm extension GraphQL tương ứng để lấy được meta SEO qua API. Tương tự cho các plugin khác bạn đang dùng mà cần lấy dữ liệu ra frontend.
Mở GraphQL IDE (WPGraphQL có sẵn trong admin) và thử query đảm bảo mọi dữ liệu cần thiết đều query được trước khi bắt đầu tích hợp. Có thể chạy thử query bên dưới để test.
{
posts(first: 5) {
nodes {
title
slug
date
content
}
}
}Nhờ Claude Code review lại dự án xem cần các size ảnh nào để ảnh hiển thị đẹp, sau đó nhờ nó tạo đoạn code cho vào mu-plugins.
Bước 7: Brainstorm và lên kế hoạch tích hợp API
Đây là bước chuyển từ “website tĩnh đẹp” sang “website headless thật sự.” Chạy lại /superpowers:brainstorm để thảo luận phương án tích hợp WPGraphQL vào frontend. Ở bước này, hãy đưa vào context tất cả kinh nghiệm và gotcha mà mình đã chia sẻ trong bài: giới hạn phân trang 100 bài của WPGraphQL, cần sanitize content HTML, cấu trúc cache với Redis, xử lý URL ảnh qua CDN, webhook invalidation.
Lưu ý: Đừng quên nói AI không bao giờ hard-code các đường dẫn, thông tin nhạy cảm vào code. Hãy luôn tách ra các thông tin này vào biến môi trường tại .env như API Endpoint, TTL của Cache,…
Sau đó /superpowers:write-plan để lên kế hoạch tích hợp chi tiết. Kế hoạch nên chia nhỏ theo từng loại trang: trang chủ trước (đơn giản nhất, chỉ cần fetch bài mới nhất), rồi trang bài viết đơn (fetch theo slug), rồi trang lưu trữ (phân trang, lọc chuyên mục), rồi tìm kiếm, rồi các trang phụ.
Bước 8: Tích hợp từng trang một
Thay thế mock data bằng dữ liệu thật từ WPGraphQL, từng trang một theo kế hoạch. Mỗi trang xong thì test kỹ trước khi sang trang tiếp theo. Đây là lúc bạn sẽ gặp phần lớn các vấn đề thực tế: content HTML từ WordPress cần sanitize, ảnh cần chuyển URL sang CDN, shortcode cũ cần xử lý, phân trang cursor-based hoạt động khác phân trang offset truyền thống.
Đừng cố tích hợp tất cả cùng lúc. Mỗi trang có vấn đề riêng, giải quyết từng cái một sẽ ít choáng ngợp hơn và dễ debug hơn nhiều.
Bước 9: Xây dựng hệ thống cache và tối ưu hiệu năng
Khi tất cả các trang đã hoạt động với dữ liệu thật, bắt đầu thêm cache. Thiết lập Redis cho response caching, cấu hình Cloudflare CDN cho static assets và HTML cache (nếu bạn dùng CloudFlare), xây dựng webhook endpoint để WordPress thông báo khi có bài mới hoặc bài sửa → tự động xóa cache liên quan.
Riêng mình thì mình có làm một plugin riêng và đóng gói lại để tái sử dụng, bao gồm tích hợp xoá cache trên CloudFlare, thông báo cho frontend qua Webhook khi cập nhật/đăng bài mới, bạn cũng có thể dùng AI tạo một dự án riêng để làm một plugin như vậy.
Ở giai đoạn này cũng nên thêm các tối ưu khác: lazy loading ảnh, prefetch link khi hover, minify HTML/CSS/JS, và đo Lighthouse để biết điểm hiệu năng cụ thể.
Tips: Bạn có thể tích hợp Chrome Dev-tools MCP cho Claude Code để nó test điểm Lighthouse tự động, tạo báo cáo và fix cho bạn luôn, nhưng cần kiểm soát kỹ nhé.
Bước này nên sử dụng /superpowers:brainstorm để tìm phương án tối ưu.
Bước 10: Tinh chỉnh bảo mật
Thêm các lớp bảo mật đã đề cập ở phần trước: sanitize content với thư viện chuyên dụng, security headers cho API endpoints, rate limiting với sliding window, webhook signature verification, giới hạn kích thước response GraphQL. Cấu hình Cloudflare firewall rules để chặn truy cập trực tiếp vào WordPress backend từ bên ngoài hoặc sử dụng Tailscale để tạo mạng riêng nội bộ.
Thông tin thêm: Để bảo mật tốt nhất, hãy dựng một VPN Server riêng bằng cách thuê một VPS giá rẻ và giới hạn mọi nơi riêng tư chỉ cho phép truy cập bằng IP của VPN này. Hoặc sử dụng Tailscale như một tiêu chuẩn bắt buộc cho toàn bộ dự án, bài viết về Tailscale mình có viết khá nhiều tại https://azdigi.com/blog
Nên nói AI đi review lại code hiện tại để nó thiết kế phương án bảo mật phù hợp nhất, có thể tham khảo từ các kinh nghiệm ở trên của mình.
Tips: Dừng lại và nhờ AI kiểm tra – đừng đợi đến cuối mới review
Sau mỗi 2-3 bước hoàn thành, dừng lại và nhờ AI quét lại code vừa viết. Không phải đợi đến cuối dự án mới review, phát hiện vấn đề sớm khi code còn ít thì fix nhanh, để cuối dự án khi code đã phình to thì một lỗi kiến trúc nhỏ có thể kéo theo hàng chục file phải sửa.
Yêu cầu AI kiểm tra ba khía cạnh: bảo mật (input chưa sanitize, endpoint thiếu rate limiting, secret key bị hardcode), hiệu năng (query N+1, thiếu cache, render không cần thiết), và chất lượng code (hàm quá dài, logic lặp lại, đặt tên không rõ ràng). Mỗi lần review chỉ mất 5-10 phút nhưng có thể tiết kiệm công sức debug sau này.
Tips: Luôn duy trì tài liệu cho AI
Mỗi khi triển khai thêm tính năng hoặc fix bug, luôn yêu cầu AI cập nhật tài liệu và thống nhất thư mục lưu tài liệu (ghi quy định rõ trong CLAUDE.md). File này là “bộ nhớ” của AI khi làm việc với codebase của bạn: cấu trúc thư mục, quy ước đặt tên, các quyết định kiến trúc đã chọn và lý do tại sao, danh sách API endpoints, cách hoạt động của cache, v.v.
Tips: Để tiết kiệm context window, nếu bạn có nhiều tài liệu thì hãy nhờ AI rút gọn lại nhưng vẫn giữ nội dung quan trọng, mỗi file tài liệu thường không qua 800 LOC (Line-of-Code).
Không có tài liệu này, mỗi lần bạn mở session Claude Code mới, AI phải đọc lại toàn bộ codebase để hiểu context, chậm, tốn token, và dễ “đi nhầm đường.” Ví dụ: bạn đã quyết định dùng cursor-based pagination thay vì offset, nhưng AI không biết nên sinh code offset → conflict với code hiện có → mất thời gian debug. Có CLAUDE.md ghi rõ quyết định này, AI đọc trước khi code và đi đúng hướng ngay từ đầu.
Quy tắc đơn giản: mỗi tính năng mới xong, nói “cập nhật vào file XXX.md với những gì vừa làm.” Mỗi bug fix xong, nói “ghi lại nguyên nhân và cách fix vào thư mục nào đó” Tích luỹ dần, sau vài tuần bạn có một bộ tài liệu chi tiết mà không cần ngồi viết riêng — và bộ tài liệu này không chỉ giúp AI mà còn giúp chính bạn khi quay lại dự án sau vài tháng.
Bước 11: Kiểm tra SEO và chuyển hướng
Trước khi go-live, kiểm tra kỹ SEO: sitemap có đúng không, meta tags có đầy đủ không, canonical URLs có chính xác không, structured data (schema.org) có hoạt động không. Quan trọng nhất: thiết lập redirect 301 cho mọi URL cũ sang URL mới nếu cấu trúc URL thay đổi. Mất redirect là mất thứ hạng tìm kiếm, sai lầm đắt giá nhất khi chuyển đổi.
Dùng công cụ như Screaming Frog hoặc Ahrefs crawl cả site cũ và site mới, so sánh danh sách URL, đảm bảo không có trang nào bị “rơi” trong quá trình chuyển đổi.
Bước 12: Backup và rollback
Trước khi chuyển DNS sang site headless mới, đảm bảo bạn có thể quay lại site WordPress cũ trong vòng 5 phút. Giữ nguyên site cũ hoạt động ít nhất 2 tuần sau khi go-live. Nếu headless gặp sự cố nghiêm trọng (cache toàn bộ bị lỗi, API WordPress sập,…), bạn chỉ cần chuyển DNS về lại là site cũ hoạt động bình thường không mất một giây downtime nào cho người đọc.
Mình cũng giữ bản backup database WordPress trước khi chuyển đổi. Quá trình chuẩn bị headless có thể yêu cầu cài thêm plugin, thay đổi cấu hình permalink, sửa content nếu có gì sai, restore backup và bắt đầu lại.
Bước 13: Deploy và theo dõi
Nếu bạn chưa biết deploy headless WordPress thế nào thì đừng ngại hỏi AI. Chạy /superpowers:brainstorm với context: framework gì, traffic dự kiến bao nhiêu, ngân sách ra sao, team có kinh nghiệm DevOps không. AI sẽ tư vấn các hướng phù hợp: Vercel/Netlify cho đơn giản nhất, VPS với Docker cho kiểm soát nhiều hơn, hoặc Kubernetes cho quy mô lớn.
Mình quen dùng Docker nên chọn ngay Docker + Docker Compose và thường luôn nhờ AI tạo Dockerfile và docker-compose.yml. Đưa context về dự án (Astro SSR, cần Redis, cần reverse proxy) là AI sinh ra cấu hình hoàn chỉnh, bạn chỉ cần review và chạy. Tiết kiệm thời gian rất nhiều so với tự viết từ đầu, đặc biệt khi cần cấu hình multi-stage build để tối ưu image size hay thiết lập health check.
Deploy lên production, nhưng chưa chuyển DNS ngay. Chạy song song site cũ và site mới một thời gian ngắn, test trên domain staging trước. Khi mọi thứ ổn định, chuyển DNS sang frontend mới. Theo dõi sát trong tuần đầu tiên: lỗi 404 trong Google Search Console, traffic giảm bất thường, tỷ lệ cache hit, thời gian phản hồi.
Bước 14: Review toàn bộ và refactor
Khi mọi tính năng đã hoàn chỉnh và website chạy ổn định, đây là lúc nhờ AI review toàn bộ codebase một lần cuối. Mục tiêu không phải tìm bug (đã fix trong quá trình) mà là refactor để bạn thực sự hiểu codebase.
Vibe coding có một nhược điểm lớn: code được sinh ra nhanh nhưng bạn chưa chắc hiểu hết. Hàm này làm gì? Tại sao logic nằm ở đây mà không phải ở kia? File này có cần thiết không? Nếu bạn nhìn vào codebase mà cảm thấy khó hiểu, đó là dấu hiệu cần refactor.
Mình thích cấu trúc code phân loại theo dạng module hoá: mỗi module chịu trách nhiệm một việc rõ ràng, có thể hiểu độc lập mà không cần đọc module khác. Ví dụ module cache chỉ lo cache, module GraphQL chỉ lo query, module sanitize chỉ lo làm sạch HTML. Nhờ AI sắp xếp lại theo cấu trúc này nếu code đang lộn xộn.
AI có thể mắc sai lầm nhưng nó lại luôn tự mặc nhiên cho là mình đúng, vì vậy hãy luôn phải kiểm tra mỗi đoạn code được thêm vào để tránh bị sai logic trầm trọng hoặc tính năng không như ý muốn, nắm rõ codebase để có thể hiểu nó hoạt động ra sao để khi có lỗi thì phán đoán được lỗi xảy ra ở đâu, từ đó chỉ rõ cho AI để fix trong thời gian nhanh nhất.
Kết bài
Chuyển thachpham.com (và cả azdigi.com) sang headless là một trong những quyết định kỹ thuật đúng đắn nhất mình từng làm: Lighthouse 95+, TTFB dưới 200ms toàn cầu (qua CloudFlare), WordPress ẩn trong private network, SEO control tuyệt đối và quan trọng nhất là trải nghiệm development tuyệt vời với các framework frontend hiện đại.
Nhưng mình cũng phải nói thật: đây không phải giải pháp cho mọi người. Headless WordPress là phải chấp nhận đánh đổi, bạn đánh đổi sự tiện lợi và hệ sinh thái phong phú của WordPress truyền thống lấy performance, security, và flexibility. Đánh đổi đó có đáng hay không phụ thuộc vào bạn, team bạn, và dự án cụ thể của bạn.
Nếu bạn quyết định thử, Claude Code + Superpowers là combo tuyệt vời để tăng tốc quá trình và mình nghĩ là nên làm vậy.
Cuối cùng, headless hay không headless, điều quan trọng nhất vẫn là nội dung. Kiến trúc đẹp nhất thế giới cũng vô nghĩa nếu blog không có gì đáng đọc. Infrastructure là phương tiện, nội dung mới là đích đến.
Chào thân ái và chúc bạn năm mới Bính Ngọ 2026 vạn sự như ý, tấn tài tấn lộc.
- https://wpengine.com/resources/achieving-better-core-web-vitals-with-headless-wordpress/ ↩︎
- https://docs.astro.build/en/concepts/islands/ ↩︎
- https://astro.build/blog/2023-web-framework-performance-report/ ↩︎
- https://www.wpbeginner.com/beginners-guide/what-is-headless-wordpress-and-should-you-use-it/ ↩︎
- https://www.wpgraphql.com/2020/03/26/forward-and-backward-pagination-with-wpgraphql ↩︎
- https://www.wpgraphql.com/docs/known-limitations ↩︎
- https://www.microsoft.com/vi-vn/security/business/security-101/what-is-zero-trust-architecture ↩︎
- https://github.com/wp-graphql/wp-graphql/issues/1357 ↩︎
- https://blazecommerce.io/blog/headless-woocommerce-a-comprehensive-guide-to-supercharging-your-store-with-blaze-commerce/ ↩︎
- https://wpengine.com/blog/state-of-headless-2024/ ↩︎
- https://www.theinsightpartners.com/reports/headless-cms-software-market ↩︎
Nếu có thắc mắc hoặc góp ý, hãy để lại bình luận bên dưới — mình sẽ phản hồi sớm nhất có thể.
Góp ý nội dung
Nếu bạn phát hiện nội dung lỗi thời, link hỏng, hoặc có góp ý cải thiện, hãy cho mình biết để cập nhật nhé.